Request Processing Units and Reactors
Decoupling User Interactions from Internal Domain Capabilities

Today is the day I finally get rid of several terms I used in recent months and in previous articles. I wrote a lot about Feature Slices and about how to apply that concept in real systems. But don’t worry: the underlying concepts did not change.
This article is about terminology and linguistic precision. It is time to clarify the language and bring the concepts into a more coherent form.
The term Feature Slice, or simply Slice, is ultimately imprecise. It emerged from a movement that tried to break away from dominant software structures built around horizontal technical layers, shared services, repositories, and heavily centralized models. For that purpose the term was useful, but it never described the actual architectural unit particularly well.
A “feature” can mean almost anything. A “slice” describes shape, not responsibility. The more I refined the underlying structure, the more obvious it became that the terminology no longer matched what I was actually describing.
The architecture I describe is not built around slices. It is built around Request Processing Units, Reactors, Interactions, Delivery Mechanisms, Providers, and an Event Store as application state.
These terms are more precise because they name responsibilities instead of shapes. RPUs describe internal domain capabilities. Reactors describe the technical response to an Interaction when several building blocks have to be coordinated. Delivery Mechanisms describe the translation between the outside world and the internal processing structure.
This article was originally published here: https://levelup.gitconnected.com/request-processing-units-and-reactors-0fba33071d3e?source=friends_link&sk=0ea397131da626244500036be16547e6
Core Philosophy
The architecture I am talking about is built around self-contained Request Processing Units (RPUs) as its primary building blocks. Earlier, I called these building blocks Feature Slices. And there was a time when I believed very strongly that these units had to contain absolutely everything, including transport protocols such as HTTP.
I no longer think that is correct because an RPU is not an external interface. It is an internal processing unit of the domain.

An RPU implements exactly one internal domain capability: one domain request, either a Command or a Query. It contains the complete responsibility for processing that request: loading relevant facts, building context, evaluating business rules, generating a result or consequences, and executing the imperative shell around the pure decision logic.
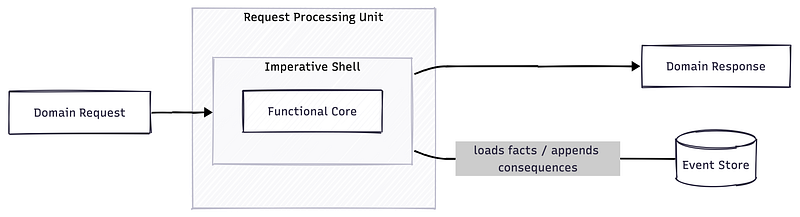
The important distinction is that RPUs are intentionally decoupled from external interactions. One external interaction may be fulfilled by exactly one RPU. But it may also require several RPUs coordinated together through what we call a Reactor.
A Reactor describes the technical response to an Interaction. It coordinates RPUs and Providers when the system needs to produce one coherent response from several building blocks. It does not own the domain decisions of the participating RPUs.
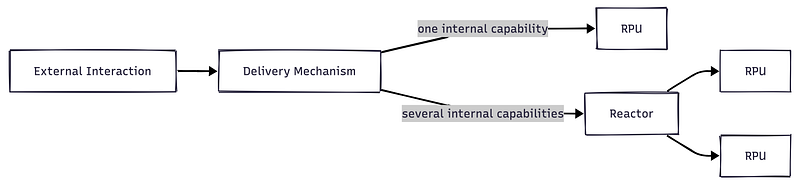
This distinction matters because external interactions and internal processing boundaries are not the same thing. Treating the external interaction itself as the architectural unit usually leads back toward oversized transactional services, broad handlers, or artificial aggregate boundaries.
The RPU building block instead allows the domain to choose its own internal granularity. The goal is maximum locality of behavior, minimal technical layering, and extreme changeability.
Duplication between RPUs is accepted intentionally. Similar logic may exist in several RPUs because independence of processing units is more valuable than aggressive DRY abstractions. RPUs do not depend on each other, and they do not reuse internal functions from other RPUs. RPUs are therefore self-sufficient and intentionally substantial. They are the place where real domain decisions happen, so they form the foundation of the domain. Reactors are different: they stay lightweight and flexible.
Shared abstractions frequently centralize behavior again and slowly reintroduce coupling between otherwise independent capabilities. Code generation can mitigate some duplication later if necessary. But locality and independence come first.
Terminology
Before going further, I want to make the core terms explicit. These are the terms I use from now on, and they describe different perspectives of the same system. Some of them are technical. Some of them describe the business view. Mixing them is exactly what created part of the confusion around the older term Feature Slice.
- RPU (Request Processing Unit): Atomic, self-contained processing unit that implements exactly one internal domain capability, which means one domain request, either a Command or a Query.
- Reactor: Optional technical integration unit that is introduced when one Interaction requires several RPUs or Providers to be coordinated. A Reactor is the technical counterpart to an Interaction: the Interaction brings the trigger from the outside, and the Reactor coordinates the immediate response of the system. It does not contain the domain decision logic of the participating RPUs.
- Interaction: The user-facing process that starts when an external trigger occurs and runs from collecting the required input to returning the output. It can be fulfilled by one RPU or by several RPUs coordinated by a Reactor.
- Use Case: Higher-level business description from the user or stakeholder perspective. A Use Case contains one or more Interactions.
- Delivery Mechanism: Thin translation layer that converts external requests, for example HTTP or CLI, into commands for an RPU or a Reactor and converts the result back into the desired output format.
- Providers: Infrastructure components that RPUs and Reactors use when they need to interact with the outside world, for example databases, ID generators, blob storage, or external APIs. Providers are always passed in from the outside and never live inside an RPU.
- Application State (Event Store): The central, single source of truth of the system. It consists of the immutable sequence of events, or facts, that all RPUs load context from and Command RPUs append new consequences to. The entire application state is derived from this event store.
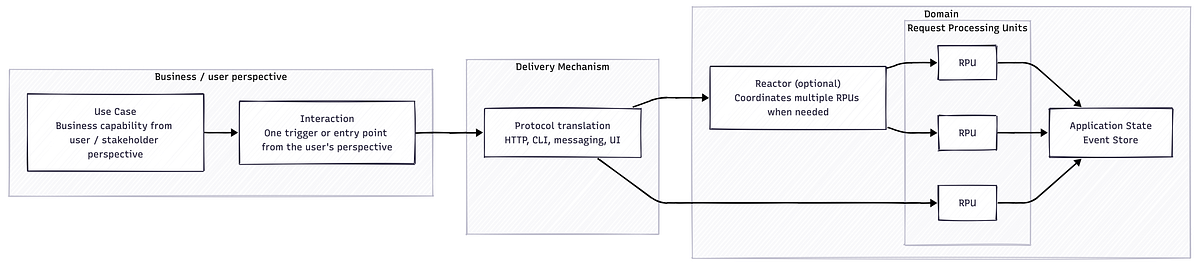
Note: In this terminology, a Reactor is not an event handler, subscriber, projection, saga, or process manager. It does not react to recorded facts after the fact. It coordinates the system response to an Interaction.
Recommended Project Structure
Here is the project structure I currently use and recommend for this approach.
The important change is that the internal processing units are named explicitly. They are not hidden behind generic folders such as services, use cases, application, or domain. The code structure should make the processing approach visible.
src/
├── rpunits/ ← All atomic RPUs
│ ├── register_tool/
│ │ ├── load_context.rs
│ │ ├── build_context.rs
│ │ ├── generate_consequences.rs ← pure Functional Core
│ │ ├── append_consequences.rs
│ │ ├── process_request.rs ← Imperative Shell (store + providers)
│ │ └── mod.rs
│ ├── check_out_tool/
│ ├── return_tool/
│ └── get_inventory/
│
├── reactors/ ← Optional, only created when needed
│ └── prepare_tool_rental/
│ ├── command.rs
│ └── process.rs ← technical response coordination
│
├── http/ ← Delivery Mechanism (protocol translation)
│ ├── routes.rs
│ └── handlers/
│ ├── register_tool_handler.rs
│ └── ...
│
├── events/ ← Pure data only
├── store.rs ← Application store
└── providers/ ← Infrastructure (database, HTTP adapter, etc.)This structure makes the distinction visible in code. Atomic processing units are placed under rpunits. Reactors are separated into reactors only when they are needed. HTTP is only one delivery mechanism and stays outside the RPUs.
The individual files inside an RPU describe the processing steps directly.
The structure is intentionally boring. It avoids generic technical buckets and keeps the important question visible: which internal request is processed here?
User Interface, Delivery Mechanism, and Presentation Concerns
RPUs and Reactors are protocol-agnostic. They are not tied to HTTP, a web UI, a CLI, or any other external delivery form.
The Delivery Mechanism translates external requests into RPU or Reactor commands and converts the result back into the required output format. Different delivery forms can translate into the same domain request without changing the RPU itself.

Some requirements have both a domain part and a presentation part. A simple example is user registration with repeated password input.
The domain rule is that both passwords must match. That rule belongs inside the responsible RPU, for example in rpunits/register_user/generate_consequences.rs.
The presentation concern is that the frontend shows two password fields and may provide immediate client-side feedback. That belongs in the user interface, for example in JavaScript.
This distinction keeps the RPU responsible for the domain request while the user interface remains responsible for how the interaction is presented to the user.
Concrete Example: prepare_tool_rental
To make the distinction more concrete, imagine a user wants to prepare a tool rental in one user-facing Interaction.
From the user’s perspective, this may look like one coherent action: a tool should be available in the system and then checked out to a team for a specific job site.
Internally, this is not necessarily one RPU.
The current tool rental example already separates the main capabilities into Register Tool, Check Out Tool, Return Tool, and Get Inventory. The command RPUs record facts such as tool-registered, tool-checked-out, and tool-returned, while Get Inventory builds the current inventory view from the recorded facts.
A Reactor such as prepare_tool_rental could coordinate two RPUs:
reactors/
└── prepare_tool_rental/
├── command.rs
└── process.rsThe Reactor receives one command for the larger interaction. It first calls the register_tool RPU when the tool is not yet known in the system. It then calls the check_out_tool RPU to check out that tool to the requesting team.
The important part is that the Reactor does not absorb the logic of those RPUs. Register Tool still owns the decision whether a tool can be registered. Check Out Tool still owns the decision whether a tool can be checked out. The Reactor only coordinates the sequence when the business interaction needs both steps.
In code, the structure could look like this:
src/
├── rpunits/
│ ├── register_tool/
│ ├── check_out_tool/
│ ├── return_tool/
│ └── get_inventory/
│
├── reactors/
│ └── prepare_tool_rental/
│ ├── command.rs
│ └── process.rs
│
└── http/
└── handlers/
└── prepare_tool_rental_handler.rsThe HTTP handler is only the delivery entry point. The Reactor is the coordination unit. The RPUs remain the atomic processing units.
Conclusion
By replacing the imprecise Feature Slice terminology with Request Processing Units, the architecture finally has clearer, more consistent, and more honest language.
RPUs give us precise, self-contained units for internal domain capabilities, intentionally decoupled from external user interactions. Reactors remain lightweight and optional. They only appear when one Interaction requires several RPUs or Providers to be coordinated as one system response.
Presentation and protocol concerns stay in the Delivery Mechanism. Domain requests are processed by RPUs. Coordination, when needed, becomes explicit through a Reactor.
The result is an architecture that maximizes locality, independence, and long-term maintainability while staying simple and focused on real business needs.
Cheers …and goodbye, Feature Slices!