Functional Core / Imperative Shell for Agentic Coding
How Repository Structure, Feature Slices, and Project-Level Skills Guide Coding Agents Toward Self-Contained Features

In my previous article, I described feature slices as boundaries of ownership. I will take that as given here and move directly to the practical question: how does a code repository have to look if an agent is supposed to generate that shape reliably?
People talk about prompting, model quality, or tool choice, while the code repository keeps teaching the agent the wrong structure. If the codebase still exposes services, controllers, repositories, managers, helpers, common folders, generic file names, and shared extension points, then those are exactly the shapes the agent will keep producing. The problem starts long before the prompt.
I want to make that concrete: which names keep inviting the wrong architecture, which names make ownership clearer, how I cut features so the decision logic stays local, how Functional Core / Imperative Shell gives the slice a usable internal shape, and how those choices have to be encoded again in skills, Codex instructions, and review rules.
A ready-to-use SKILL.md template is linked at the end of the article for anyone who wants to apply this structure directly in a project.
The Project Structure Instructs the Agent Before the Prompt Does
In one codebase, the generated change extends an existing service, adds another data-access abstraction, and pushes more logic into a shared area. In another, the same task turns into a self-contained feature with local naming and an explicit execution flow. The difference is what the code repository already presents as normal.

A weak instruction leaves too much of the internal structure open. A stronger one closes the most damaging escape routes early: no services, no controllers, no repository pattern, no helpers, no managers, no shared fallback, no generic file names when behavior-specific names are possible. At that point the instruction stops being a feature request and starts becoming a structural constraint.
A folder called register_client does not solve much if the files inside still use generic technical names such as service, logic, manager, or repository. Those names already pull the result back toward technical categories. If the files are called load_registration_context, decide_registration, append_registration, and registration_state, the feature starts to describe its own execution directly.
A feature should not contain files with generic technical names. Names such as service.rs, logic.rs, manager.rs, repository.rs, util.rs, or helper.rs already pull the structure back toward technical categories instead of behavior. Inside a slice, file names should describe the actual work being done, especially at the boundary and in the decision flow. Names such as load_registration_context.rs, decide_registration.rs, append_registration.rs, query_parameters.rs, or error_responses.rs make the execution easier to understand directly from the feature itself.
The code repository, the skill file, and the Codex or Claude Code instruction all need to point in the same direction.
Functional Core / Imperative Shell Gives the Slice an Internal Form
A feature-specific directory and meaningful file names still leave one practical question open: how should the feature be structured internally?
I do not mean it here as a general architecture topic, but as a concrete way to shape a self-contained feature.
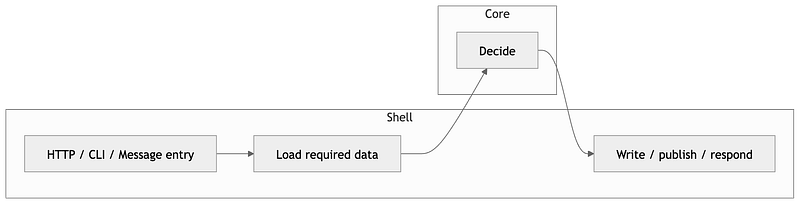
The shell handles the entry, the loading, and the external effect. The core carries the actual decision. That gives the slice a readable internal execution flow without falling back to services, managers, or other generic technical roles.
For a coding agent, the same structural intent can be made explicit in instructions like these.
### 3. Functional Core, Imperative Shell
* Core = pure, deterministic decision logic
* Shell = boundaries and effects only (HTTP, DB, external systems)
* The shell may load data and persist results
* The core must not perform IO
Never mix both.
### 4. Explicit IO boundaries
* IO is visible and isolated
* No hidden IO inside coreIn a feature like register_client, names such as load_registration_context, decide_registration, and append_registration already reflect that shape directly. The loading step belongs to the shell. The decision belongs to the core. The write step belongs back to the shell. The structure inside the slice should describe how the feature runs, not which architectural category a file belongs to.
Share Nothing That Carries Domain Meaning
A self-contained feature is easier to generate, easier to change, and easier to replace because it does not depend on shared domain-specific structures outside of itself. The shell and the core stay inside the feature. The feature can use bootstrapped infrastructure such as a database pool, an HTTP client, a logger, or configuration, but the behavior that gives the feature its meaning does not live in a shared service, shared model, or shared helper somewhere else.
A feature can be implemented with much less surrounding context when the code repository does not force the agent to understand a separate domain layer, a generic service layer, and a reusable data-access layer before it can make a local change. The feature owns the behavior it needs. The structure around it stays thin.
Once data is treated as explicit input and explicit output, the pressure toward shared mutable structures drops with it. The feature does not need a central object that carries the current meaning of the system. It needs the data required for its own decision, and it needs a clear way to write its result back. That keeps the internal contract of the feature smaller and easier to generate correctly.
A structure like this keeps the dependency surface narrow:
/register_client/
load_registration_context.rs
decide_registration.rs
append_registration.rs
vs.
/register_client/
handler.rs
/domain/
client_service.rs
/data/
client_repository.rsThe first shape keeps the feature implementable from its own slice. The second shape makes the feature depend on domain-specific structures that are shared across other behavior as well.
A self-contained feature should be replaceable. That is one of the strongest practical tests. If a feature depends on shared domain-specific structures, replacing or regenerating it is immediately more expensive. The agent has to preserve conventions outside the feature, understand behavior that is only partially visible from the slice itself, and avoid changing abstractions that other parts of the system also depend on. The feature stops being a local unit and turns into a participant in shared ownership again.
Why This Shape Works So Well with Agents
It reduces how much surrounding context is needed before a change can be made safely. A human can jump across the codebase, keep partial knowledge in mind, compensate for weak boundaries, and gradually reconstruct how shared models, services, and abstractions interact. An agent has a much narrower working surface. The more behavior depends on centralized structures outside of the feature, the more context has to be pulled in before the change is even understandable.
The shell makes the entry and the side effects visible. The core makes the actual decision visible. The feature can be implemented, reviewed, and changed from its own boundary without first understanding a domain model, a service layer, and a reusable abstraction stack somewhere else in the codebase.
It keeps the cognitive load where the feature already is. The agent does not have to reconstruct the system around the feature before it can work on the feature itself.
Project-Level Skills Teach the Agent How Features Are Built Here
A skill does not belong inside a feature. Instead, it sits one level above and teaches the agent how features in this project should be built. The feature is the generated result. The skill defines the generation environment.
your-project/
.codex/
skills/
feature-slice-rust/
SKILL.md
src/
features/
register_client/
evaluate_route_access/A prompt may ask for a self-contained feature, but the code repository may still contain shared abstractions, generic technical names, and existing extension points that keep pulling the result back into the old shape. A project-level skill counters that directly. It gives the agent a reusable instruction that applies across all features in the codebase, not just the one task in front of it.
“Implement client registration…” is not enough. The skill has to say how a feature is shaped here. It has to forbid the generic fallback structures, require meaningful file names, keep the core pure, keep IO explicit, and reject cross-feature dependencies as a default move.
This is what that can look like in practice for a coding agent.
---
name: feature-slice
description:
Create or modify a self-contained feature slice using domain-driven naming,
strict isolation, and explicit IO boundaries. No shared logic,
no cross-feature dependencies.
---
## Non-negotiable rules
### 1. Feature isolation
* Everything lives in `features/<feature-name>/`
* No imports from other features
* No shared folders (`common`, `shared`, `utils`, etc.)
* No global abstractions
### 2. No OOP structures
* No classes
* No services, managers, repositories
* No inheritanceIt tells the agent that features in this codebase are not assembled from services and shared abstractions. They are built as self-contained slices with explicit boundaries and names that describe behavior directly. It stops being another place to restate the task and becomes part of the structure that keeps generated code from drifting back into the same old defaults.
Cross-Feature Dependencies Must Stay Exceptional
A feature stops being self-contained as soon as its behavior depends on the internal behavior of another feature. That is one of the easiest ways for ownership to leak back out of the slice.
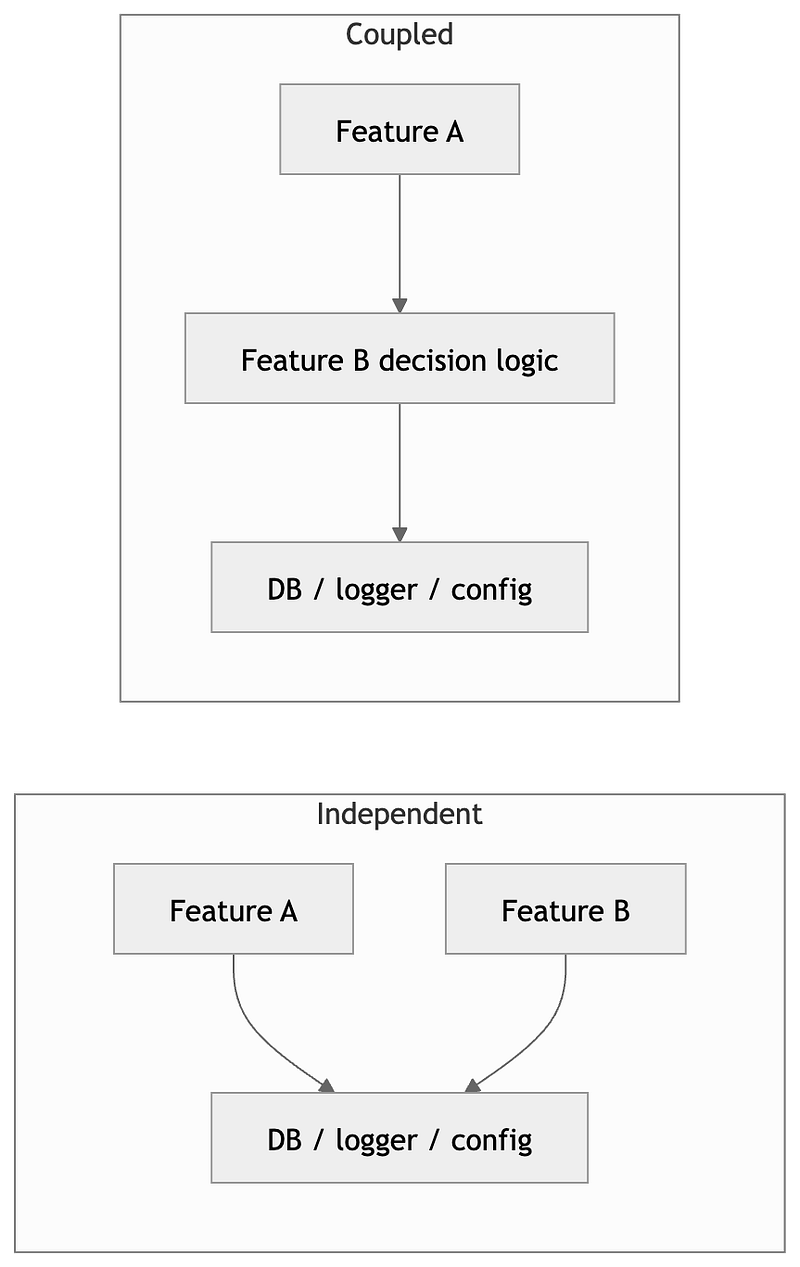
This is where a strict default matters. The normal case should be no cross-feature dependency at all. A feature can use bootstrapped infrastructure such as a database pool, a logger, configuration, or an external client. It can also depend on stable external contracts where that is necessary. But it should not reach into another feature to reuse decision logic, internal loaders, write steps, or domain-specific helpers.
The moment one feature starts depending on another feature’s internal behavior, a local change stops being local. Regenerating the slice, replacing it, or even reviewing it now requires understanding behavior that lives somewhere else. The folder still looks separate but the ownership already is not.
Two features may both validate an address, classify a client, or compute a price-related decision. That does not automatically justify one shared abstraction between them. The question is stricter than that. Do they actually need to change together for the same reason? If not, the extraction creates coupling where the slice should have remained independent. Cross-feature dependencies are not a normal optimization. They are a structural exception and should be treated that way.
For a coding agent, the structural intent can be made explicit in instructions like these.
## Dependency rules
- A feature must not import another feature's internal decision logic
- A feature must not depend on another feature's internal loaders or write steps
- Shared domain-specific helpers are not allowed as a default destination
- Cross-feature dependencies require explicit justification
- Shared infrastructure is allowed:
- database pool
- logger
- configuration
- external clients
- Stable external contracts are allowed where neededWithout it, a project can have feature folders, meaningful file names, an imperative shell, and a pure core, and still slide back into shared ownership through imports that cross the slice boundary. The structure stays visible. The independence is gone.
A useful practical test is this: can the feature still be changed, regenerated, or replaced from its own slice without pulling domain-specific behavior in from somewhere else? If the answer is no, the dependency has already gone too far.
Conclusion
Agentic coding does not reward codebases that leave structure implicit and hope the agent will infer the right shape. It rewards codebases that make feature boundaries, naming, dependencies, and execution form explicit from the start.
That is why this is not only a prompting topic. It is an engineering topic. The more clearly the project encodes how features are supposed to be built, the less room remains for the old object-oriented defaults to reappear under a new name.
The full project-level skills behind these examples can be found here: https://github.com/ricofritzsche/agentic-feature-slice-templates
Cheers!
This article was originally published on my Medium account here: https://levelup.gitconnected.com/functional-core-imperative-shell-for-agentic-coding-45f04beb55f5