Lean Architecture with .NET Core and C#
How to Avoid Unnecessary Complexity and Keep Your Domain Free of Technical Concerns

In this article, I want to show how easy it is to keep the domain free of technical concerns. In my past articles, I've written about distinguishing between data models, persistence, and domain models.
One reasonable question I often hear is whether this might lead to code duplications, having similar models in the data and the domain model. And that’s true. Often, there are no significant differences between the data structures of these two models in a system.
In the past, I tended to have a pure domain model without any annotations or knowledge in the core of my application and a separate data model in the infrastructure layer, mapping the data in both directions. But to be honest, this is not lean and always feels over-engineered. When there is no strong justification for this, I think it’s best not to do it. There is a much better way to keep the code lean and clean while keeping the concerns separated.
The Importance of Business Value
While working on my new Location Services API venture over the past few weeks, I recognized that it is crucial to create solutions that are robust, secure, and scalable, but foremost useful. Anything we do in code must have a business value. Otherwise, it’s wasted time.
This is what I often see in development teams: there is no good balance between what is needed to create value for users and the company and what is done just to satisfy patterns and use the latest frameworks. We should find a good balance and not blindly follow highly promoted architecture approaches and patterns without fully understanding the value of the product and domain.
My Approach to Lean Code
Let me tell you more about my motivations and the approach I chose to produce value immediately while keeping the code lean and clean, maintainable, and easy to understand.
In recent months, it has become more important to me to keep together things that are needed to fulfill a specific task. That’s why I prefer to think in feature slices, meaning to cut the code into small functional units vertically.
For example, having a feature like Register Tenant is such a slice. Everything needed to register a new tenant must be located in this feature slice. It doesn’t matter if it’s just an API endpoint or a view or both; it is part of the interaction between the consumer and the machine. Another slice or task that the system must fulfill could be a feature slice like Get Tenant By Id, which is a read-only operation, while the first example, Register Tenant, is changing something.
Command Query Separation (CQS)
By doing this, we automatically keep commands separated from queries, meaning we apply CQS (Command Query Separation). Following the vertical slicing approach is a concrete method to apply CQS.
This idea was first put forward by Bertrand Meyer in his 1988 book "Object-Oriented Software Construction". Meyer's big point was pretty straightforward: when you're coding, make sure a function either changes something or returns some information, but it shouldn't do both.
CQS brings some clear benefits by introducing Separation of Concerns (SoC). This means that we keep the code that reads data and the code that changes data completely separate. Such a separation, right there in the code, naturally leads to a cleaner organization, whether we're talking about organizing methods or classes.
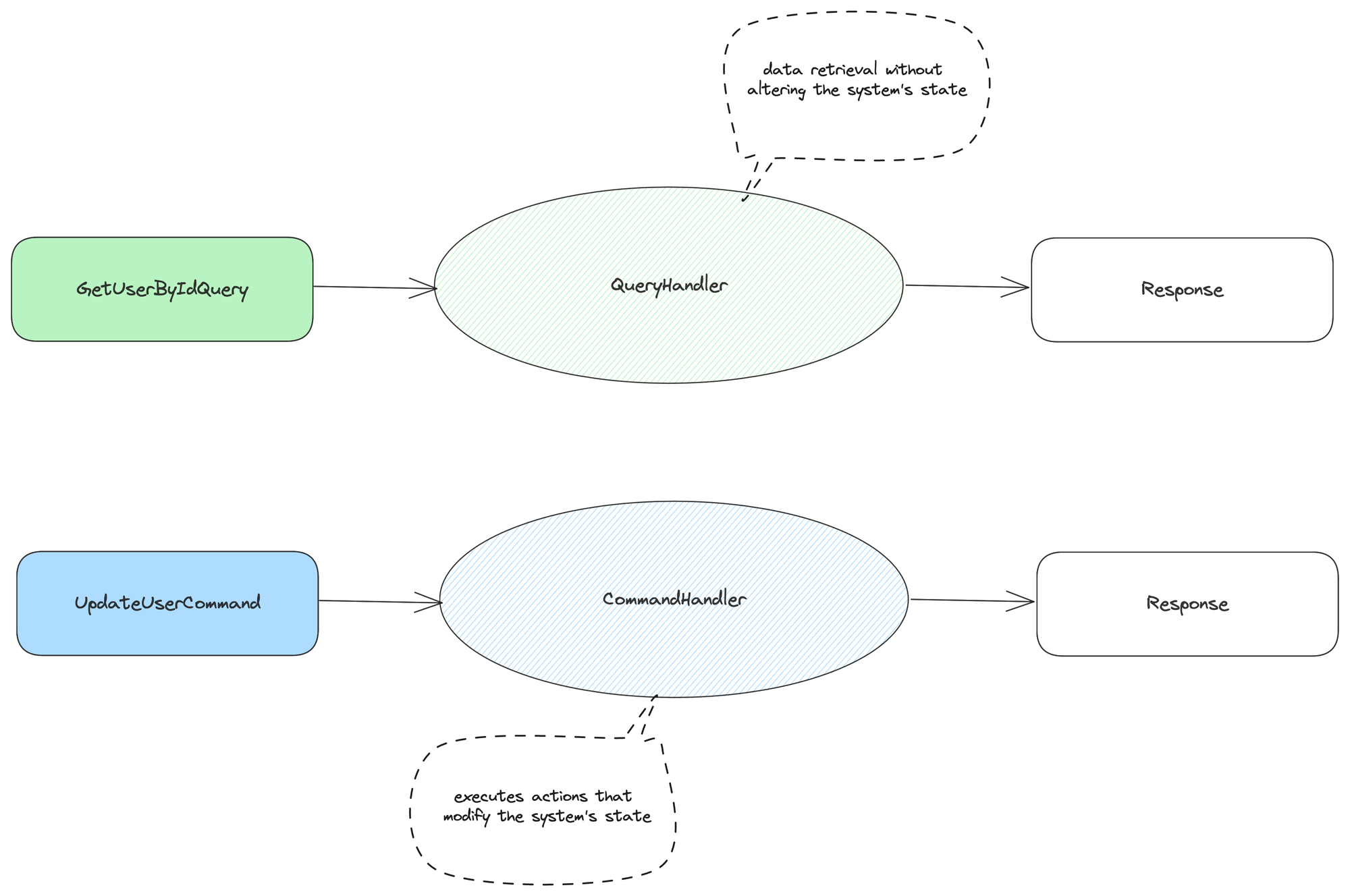
When all the code is kept close together, we achieve high cohesion inside the slice but decoupled from each other.
Benefits of Vertical Slicing
This is a fantastic way to produce easy-to-extend code, where each feature encapsulates everything needed to fulfill the task instead of having the code spread over different layers like traditional horizontal layer approaches such as Clean Architecture and Hexagonal Architecture promote.
I used these layered architecture approaches for many years, always starting with good intentions, but they often ended up too complex. Thinking in horizontal layers often leads to “god” service classes such as a typical Tenant Service that accidentally contain both commands and queries.
Avoiding Duplicated Code and Maintaining Consistency
The most interesting question with vertical slicing is how to avoid duplicated code and how to deal with domain consistency and data models without ending up in a layered architecture. We still need a reasonable separation of concerns but must find a way to keep the incredible benefits of the vertical slice approach, allowing us to include only what’s needed to fulfill the task within a slice.
Practical Example
I always try to think technology-agnostic. I have used different programming languages and technologies in my career and learned to have different views. What I like about Spring Boot, for example, is the idea of packages that ensure independent modules within the system when used correctly. A package can be a bounded context in terms of Domain-Driven Design, defining a clear boundary of a specific module of a particular domain.
In .NET solutions, a bounded context is technically a class library, aka a .NET project. It’s an independent, viable package.
Since this article is not about structuring different bounded contexts in a solution or making them deployable as (modular) monoliths or microservices, I won’t discuss this topic further here, but in one of my next articles.
Structuring Code Inside a Package
The core issue of this article is how the code could be structured inside a package, aka bounded context, avoiding unnecessary layers and abstractions while keeping clean concerns separated. In most applications, we need a place where the domain logic is located, meaning where we cluster the bounded context into aggregates as modules ensuring consistency.
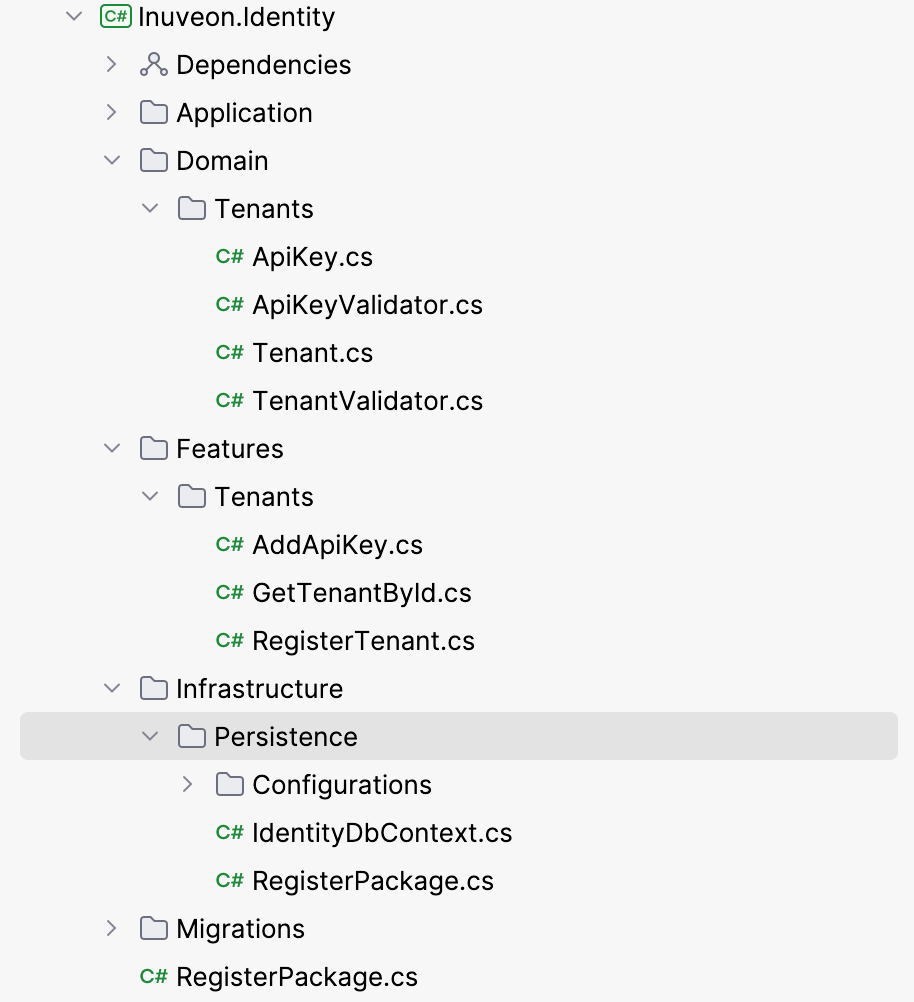
In the figure above we see a typical structure that I prefer to organize the code in a very clear way. I will discuss the internal structure of the features in another episode of this series. The fact that the domain model contains the structure but has no knowledge of how it is persisted is important for today's discussion.
Using an Event Store and Event Sourcing for write operations, along with projections for read operations, is also an option. This setup ensures that the read model event handler is notified about changes to an aggregate, keeping everything in sync. While this approach provides a clear separation of concerns and effectively implements Command Query Responsibility Segregation (CQRS), it also introduces additional complexity. Although I appreciate the benefits of CQRS and Event Sourcing, they do not add significant value to my API venture.
Keeping It Simple
Since I don't need history or to repeat events, many of my requirements are related to creating new data or updating existing data. My main goal is to keep the code simple, easy to understand, and separate concerns.
I want to avoid duplicating data structures of my aggregates in data models, ending up in mappings. Some might suggest using mapper libraries, but for me, it’s just another dependency to manage. It’s better to avoid it when not needed.
Separation of domain and persistence concerns is quite simple in .NET using the Entity Framework without using attributes as most commonly used.
I have identified three technical concerns I want to separate: the domain itself, vertical sliced features, and underlying data structures. The domain should be clean from any technical aspects but contain logic and rules, clustered as aggregates. The vertical sliced features could be commands (changing things) or queries (reading), following the same interaction patterns: request => request processing => response as shown in the following example.

A slice should contain anything needed to process a request and give the response.
So lets have a look in one of my aggregate root classes which contains the data structure of the Tenant but also validations, rules and logic.
public class Tenant : BaseEntity<TenantValidator>, IAggregateRoot
{
protected Tenant()
{
}
public string CompanyName { get; init; }
public string? Industry { get; init; }
public string CompanyEmail { get; init; }
private readonly List<ApiKey> _apiKeys = new();
public IReadOnlyCollection<ApiKey> ApiKeys => _apiKeys.AsReadOnly();
public void AddApiKey(TimeSpan expiration)
{
var apiKey = ApiKey.Create(this.Id, expiration);
_apiKeys.Add(apiKey);
}
public static Tenant Create(string name, string email)
{
var tenant = new Tenant
{
Id = Guid.NewGuid(),
CompanyName = name,
CompanyEmail = email
};
tenant.Validate();
return tenant;
}
}As you can see, there is no trace of persistence. It is pure C# code that maps the domain concerns. Of course, we want to persist the state without enriching the domain model with knowledge about database issues. This is easily possible in .NET with the help of the EF Core Framework. But how to do it?
To keep the domain model clean and free of persistence concerns, we use the EntityTypeBuilder to configure the mappings for our entities. This approach ensures that our domain models remain focused on the business logic, while the infrastructure layer handles the database-specific details.
In the /Infrastructure/Persistence/Configuration folder, I use the EntityTypeBuilder of the EF Core Framework to describe the persistence configuration. Here is an example:
public class TenantConfiguration : IEntityTypeConfiguration<Tenant>
{
public void Configure(EntityTypeBuilder<Tenant> builder)
{
builder.ToTable("tenants", "identity");
builder.HasKey(t => t.Id);
builder.Property(t => t.Id)
.HasColumnName("id")
.IsRequired()
.ValueGeneratedNever();
builder.Property(t => t.Industry)
.HasColumnName("industry")
.HasMaxLength(100);
builder.Property(t => t.CompanyName)
.HasColumnName("company_name")
.IsRequired()
.HasMaxLength(100);
builder.Property(t => t.CompanyEmail)
.HasColumnName("company_email")
.IsRequired()
.HasMaxLength(100);
builder.Property(t => t.CreatedAt)
.HasColumnName("created_at")
.IsRequired();
builder.Property(t => t.UpdatedAt)
.HasColumnName("updated_at");
}
}In this configuration, I define how the Tenant entity maps to the database schema. The ToTable method specifies the table name and schema. The HasKey method sets the primary key. Each Property method maps a domain property to a database column with its specific attributes, such as IsRequired, HasColumnName, and HasMaxLength.
By using the EntityTypeBuilder, I keep the domain model free from persistence concerns, maintaining a clean separation of concerns. This way, my domain models remain pure, focusing solely on business logic while EF Core handles the database mapping in the infrastructure layer. This approach helps maintain a lean and clean codebase.
Wiring Up EntityBuilder Configurations in the DbContext
Here's how to wire up the entity configurations like TenantConfiguration in the DbContext implementation.
We start by defining our DbContext class, where we specify the database sets and apply the configurations. Below is an example of how to implement this:
public class IdentityDbContext(DbContextOptions<IdentityDbContext> options) : DbContext(options)
{
public DbSet<Tenant> Tenants { get; set; }
public DbSet<ApiKey> ApiKeys { get; set; }
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
base.OnModelCreating(modelBuilder);
modelBuilder
.ApplyConfiguration(new TenantConfiguration())
.ApplyConfiguration(new ApiKeyConfiguration());
}
}By applying these configurations in the OnModelCreating method, we ensure that the entity mappings are centralized and maintained in a single place, keeping the domain model free from persistence concerns. This approach adheres to the principle of separation of concerns, making the codebase easier to manage and extend.
Conclusion
In conclusion, achieving a lean architecture in .NET Core involves focusing on business value and maintaining a clear separation of concerns. By adopting vertical slicing, we can encapsulate features into small functional units, enhancing code maintainability and readability. CQS further helps in organizing the code by separating read and write operations, leading to a more structured and efficient application.
We can avoid over-engineering by resisting the urge to blindly follow popular architecture patterns and frameworks without understanding their value to the product and domain. Instead, we should adopt approaches that simplify our code and focus on business logic, such as using the EntityTypeBuilder in EF Core to manage persistence concerns without polluting our domain models.
By keeping the domain models pure and focusing on what truly matters—delivering value to users and the company—we can build robust, secure, and scalable .NET Core applications that are easy to understand and maintain. This approach reduces complexity and ensures that our efforts are aligned with business goals, ultimately leading to more successful and impactful software projects.
Cheers!