Immutability in Data Flows for Safer, Simpler Code
How Immutable Data Improves Reasoning, Safety, and Testability

In my previous article, I demonstrated the power of a functional core, imperative shell architecture in Rust to achieve testable logic and clear boundaries. A key principle underpinning this approach is immutable data flow, which means treating data as immutable values rather than mutable, stateful objects. In this follow-up, we will explore the core principles of immutability in data flows, and why immutable data objects (as used in a functional core) offer significant advantages over traditional mutable patterns (e.g., using setters to update state). We will explore how immutable state leads to better reasoning about code, fewer side effects, safer concurrency, and easier testing. Along the way, we'll use practical examples in JavaScript and Rust to compare mutable and immutable data handling. We'll pay particular attention to why Rust is particularly well suited to immutability; from its ownership and borrow checkers, which enforce safe mutations, to powerful features like pattern matching and enums, which naturally encourage an immutable, functional style.
Immutable Data Flows
A quick recap: the Functional Core, Imperative Shell paradigm divides an application into a pure, logic-focused core and an outer shell that handles side effects. The functional core deals with domain logic using pure functions and accepts inputs and produces outputs without altering external state. The imperative shell is in charge of real-world side effects (database I/O, HTTP calls, etc.), but it calls into the core for pure computations. This separation reduces complexity and improves testability by keeping side effects out of the core business logic.
One crucial technique that makes a functional core possible is treating data as immutable as it flows through the system. In an immutable data flow, data is never modified in-place. Instead of objects that carry state which gets mutated over time, we use values that, once created, do not change. Any "change" to data is represented by producing a new data object and leaving the original untouched. This is in contrast to the typical object-oriented mutable pattern, where an object’s fields can be updated via setter methods or by direct assignment, meaning the same object’s state evolves over time.
By embracing immutability in the core, we ensure that domain functions have no hidden side effects. Given the same input, an immutable pure function will always produce the same output without altering any external state. This makes the flow of data easier to follow and reason about. Data goes in, data comes out, and nothing else changes in between.
In practice, adopting immutable data flows means that when the imperative shell layer receives input (say, an HTTP request or a database record), it converts it into immutable domain objects. These are passed into the functional core for processing. The core functions return new immutable objects (or simple values) as results, which the shell then uses to produce outputs (sending a response, updating the database, etc.). At no point does the core mutate a shared state or global variable; any necessary state changes are handled by the shell in a controlled manner (e.g. saving a new record to the DB) rather than by the core logic itself.
Mutable vs. Immutable State: Understanding the Difference
Before diving into benefits, let's clarify the difference between mutable and immutable state in a program’s data flow:
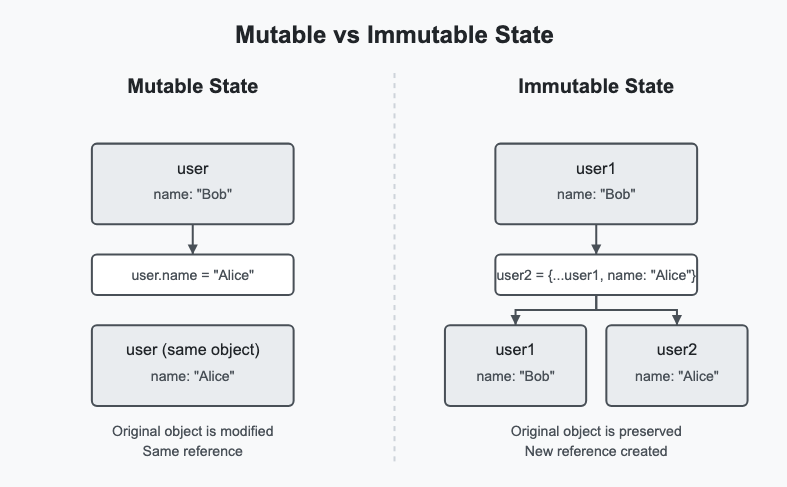
- Mutable state means that the state of an object can be changed after it's created. For example, you might have a User object and call user.setName("Alice") to change the name of the user, or change it by direct assignment (user.name = "Alice"). The same User instance now has new data. Mutable patterns often rely on setters or direct field mutations to update state.
- Immutable state means that once an object (or value) is created, it cannot be changed. To 'change' an immutable object, you create a new object with the updated value. For example, instead of calling setName, you would create a new User object that is identical to the old one, but with the Name field set to "Alice", leaving the original user unchanged. In languages such as JavaScript or Python, this often means using techniques such as object spreading ({ ...oldObj, changedProp: newValue }) or library functions to create new copies. In purely functional languages (Haskell, Clojure, etc.), all data structures are immutable by default, so any update will return a new structure.
Mutable patterns with setters can make data flows harder to follow. If multiple parts of your code hold a reference to a mutable object, a change in one place will be visible everywhere that object is referenced, unfortunately sometimes unexpectedly. For example, if you pass an object to two functions and the second function mutates it, the first function’s view of that object is also affected, even though it had no idea about the change. This "action at a distance" can introduce bugs that are difficult to trace. You might find yourself wondering "who changed this value?" or "when did this object’s state flip from X to Y?" during debugging.
By contrast, immutable data objects act like snapshots of state. If you pass an immutable object to two functions, and one of them creates a new object to represent a change, the other function still sees the original, unmodified snapshot. There is no surprise modification happening behind the scenes. Any change is explicit: a new value is returned and you can clearly see in the code where that new value came into existence. This leads to a more transparent data flow. In essence, immutability turns state changes into value transformations. Each function takes an input value and computes an output value, without ever hidden modifying the input. This aligns perfectly with the functional core idea of having clear inputs and outputs and no side-effecting operations in between.
Benefits of Immutability
Why go through the trouble of creating new objects for every change? It turns out that embracing immutability yields several major benefits.
Immutable code is easier to understand because variables don't change unexpectedly. Once an object is created, its properties remain fixed, making it easy to predict its behavior. You don't have to mentally keep track of how a piece of data might evolve elsewhere in the program, because it won't. This often leads to improved readability of the code, as you can treat each value as a constant fact, and the traceability of changes is improved.
By avoiding in-place mutations, we reduce side effects. A side-effect is any change in system state or observable interaction with the outside world that occurs during function execution (such as modifying a global variable, or updating an object that exists outside the function). Immutability naturally limits side effects, because functions can't change existing objects, they can only create new ones. This makes functions closer to pure, which means less chance of unintended interactions. Code that avoids side effects is less prone to bizarre bugs, where one part of the system inadvertently breaks something in another. For example, if an object is immutable, once you have verified that its state is correct, you can trust that it will remain valid throughout its lifetime; no background thread or other code will change it without your knowledge. This leads to improved safety in the code.
In a functional core context, this is critical: domain logic can run without worrying that some external state will be changed midway. Any necessary external change is performed in the imperative shell after the pure logic computes the new desired state.
Immutability greatly simplifies concurrent programming. If multiple threads or asynchronous tasks share access to some data, mutable state would require careful synchronization (locks, mutexes, etc.) to avoid race conditions (e.g. two threads updating a value at the same time). Immutable data, on the other hand, can be freely shared between threads because no thread can modify it. There is no risk of two threads racing to modify it. This eliminates the need for locks in many scenarios, which both avoids complexity and improves performance by avoiding conflicts. If all concurrently accessed data is immutable and all functions are pure, then dangerous concurrency hazards are avoided. If some data is mutable, then things get tricky and synchronization is needed to make accesses safe.
In Rust. for instance, the compiler enforces at compile time that data races are impossible for this very reason. You cannot have an unsynchronized mutable reference to data shared between threads. Immutability thus enables what Rust calls fearless concurrency, because you can confidently share and use data in multiple threads without fear of low-level race conditions.
Code that avoids mutable state is generally easier to test. If the output of a function depends only on its input, and not on some hidden mutable state, then you can test it by simply calling it with a variety of inputs and asserting the outputs. There's no need to set up complex object graphs or reset global variables between tests. You also reduce the reliance on mocking in your tests. There is no need to mock an object just to intercept or check that a particular field has been set; you can check the value returned directly. Debugging is also simplified because state doesn't change unexpectedly, and bugs are easier to reproduce and reason about. Since the state of an immutable object doesn't change, it's much easier to test code and find bugs. If something does go wrong, you can pinpoint which transformation produced an incorrect value because each transformation is explicit and isolated.
Mutable vs. Immutable Data Handling in Practice
Let's go through a simple scenario in JavaScript to compare mutable and immutable data handling. I'll use a very simple example of manipulating a user's name data to demonstrate the concepts.
Example: Updating an Object
JavaScript (but also C#, Java, etc.) makes it very easy to use mutable state because any object can be changed at will. For example, consider an object representing a user:
// Mutable approach: modify the object in-place
function lowerCaseNameInPlace(user) {
user.firstName = user.firstName.toLowerCase();
user.lastName = user.lastName.toLowerCase();
}
const userA = { firstName: "John", lastName: "DOE" };
lowerCaseNameInPlace(userA);
console.log(userA);
// Output: { firstName: "john", lastName: "doe" } (userA was mutated)
In the code above, lowerCaseNameInPlace takes a User object and mutates it by setting its FirstName and LastName to lowercase. After calling the function, userA itself has been changed. If there were other references to the same userA object, they would also see the updated name. This may be an unintended side effect if those references weren't expecting userA to change.
Now contrast this with an immutable approach in JavaScript, where we create a new object for the modified data, rather than modifying the original:
// Immutable approach: return a new object instead of mutating
function lowerCaseName(user) {
return {
firstName: user.firstName.toLowerCase(),
lastName: user.lastName.toLowerCase()
};
}
const userB = { firstName: "John", lastName: "DOE" };
const userBLower = lowerCaseName(userB);
console.log(userB);
// Output: { firstName: "John", lastName: "DOE" } (userB remains unchanged)
console.log(userBLower);
// Output: { firstName: "john", lastName: "doe" } (new object with lowercased names)
Even in this simple example, the benefits of the immutable approach are obvious in terms of predictability: userB is guaranteed to remain the same after the function call, so if some other piece of code relies on userB remaining uppercase, it still does. In the mutable version, that other code could break because userA has been changed without its knowledge. When building applications, for example using frameworks like React/Redux in the JavaScript world, this immutable update pattern is extremely common to ensure that state changes are predictable and traceable (Redux even enforces that reducers must not mutate state).
Pattern Matching and Enums for State Changes
Rust is a programming language with strong support for immutability. In Rust, values are immutable by default. You must explicitly choose mutability using the mut keyword. This design encourages you to think carefully about where mutation is really needed.
Let's look at a more domain-oriented example, inspired by the earlier geofencing scenario from my previous article.
Rust's immutability strengths really shine when you use enums and pattern matching to manage state transitions or variations in state. Enums in Rust let you define a type by enumerating its possible variants (a kind of algebraic data type), and pattern matching lets you safely destructure and handle each variant. This leads to code that represents state cleanly, without mutable flags or complex logic.
Suppose we have an enum representing whether an asset is inside or outside a geofence:
enum GeofenceStatus { Inside, Outside }And another enum for the movement event that might occur when a new location update comes in:
enum Movement { Entered, Exited, StayedInside, StayedOutside, Unknown }
We want a function that, given the previous status of an asset (if any) and the new status, determines the movement event (e.g. if it was outside and now inside, that's an "Entered" event, if it remained inside, that's "StayedInside", etc.). We can write this in Rust using pattern matching on a tuple of the old and new status:
fn compare_status(old: Option<GeofenceStatus>, new: GeofenceStatus) -> Movement {
match (old, new) {
(Some(GeofenceStatus::Outside), GeofenceStatus::Inside) => Movement::Entered,
(Some(GeofenceStatus::Inside), GeofenceStatus::Outside) => Movement::Exited,
(Some(GeofenceStatus::Inside), GeofenceStatus::Inside) => Movement::StayedInside,
(Some(GeofenceStatus::Outside), GeofenceStatus::Outside) => Movement::StayedOutside,
_ => Movement::Unknown,
}
}
This compare_status function is a pure, unchanging function that examines the inputs and returns a new movement value without modifying anything in place. The use of enums and pattern matching makes it very clear how the output is derived from the inputs. Each arm of the match covers a possible combination of previous and new states, yielding the corresponding motion. There is no need for a mutable object to track state internally; we don't do anything like self.lastStatus = newStatus or self.lastMovement = ... here. If we were writing this in a mutable OOP style, we might have a class like AssetTracker with a method that updates its internal state fields and returns nothing (or returns the event after side-effecting its fields).
In this approach, we simply take the old state and the new state as values and calculate another value. The caller can decide what to do with this movement, e.g. log it or send a notification, and if necessary store the new state somewhere (probably in the imperative shell layer, e.g. update the database record for the asset's last known state). The core logic remains free of side effects.
This example shows why Rust is great for designing immutable data flows: the language encourages you to use strong types (enums for states) and pattern matching to make transitions explicit. We didn't need a bunch of if/else statements with flags, nor did we mutate any objects; we considered all possible cases in a clear, declarative way. Rust's enums also ensure that if we add a new variant (say GeofenceStatus::Unknown) in the future, the compiler will force us to address it in the match (or use a catch-all _ as we did for safety). This results in very robust logic that's easy to test extensively. We can feed in different combinations of old/new statuses and check the function's output without any setup or side effects.
Conclusion
Immutability in data flows isn't just a theoretical ideal from functional programming. It is a very practical tool for managing complexity in real-world software. By using immutable data objects instead of mutable ones with setters, we gain clarity (we know where and when data changes), safety (fewer side effects and no unintended interactions), concurrency without fear (immutable data can be shared freely, enabling parallelism), and ease of testing (pure functions are a tester's dream). These benefits address the very problems that plague large codebases: unpredictable behavior, difficult debugging, and code that's hard to extend or reuse.
Cheers!