How I Built an Aggregateless Event Store with TypeScript and PostgreSQL
A Practical Guide to Event Sourcing with Pure Functions, Query Filters, Optimistic Locking, and Without DDD Aggregates

I’m picking up from my two of my latest posts, Functional Event Sourcing and Aggregateless Event Sourcing. In those pieces I showed why we can drop aggregates, shared object graphs, and the everyday habits from mainstream object -oriented thinking (yes, I know that Alan Kay’s original idea was different). We also drop the idea of central, universal entities, which is also anchored in object-oriented thinking: "a person is a person is a person".
The core idea is simple: each feature slice is fully self-contained. It pulls only the events it needs, folds them into the state required by the current command, and ignores everything else. Events are the one thing what all the features share, everything else stays local. After those posts the main question was sometimes:
“Nice theory, but how do I build it?”
This post is my answer. I’ll walk through a working event store. It runs on plain PostgreSQL, uses TypeScript for the examples, and stays 100 % framework-free. I used the same pattern in Rust originally for an internal event store in a large asset-tracking system handling millions of events. The TypeScript version follows the same core logic.
The goal is not to sell you yet another library. The goal is to show how the idea survives contact with real code. Let's discover optimistic locking, query filters, and so on while staying small enough to understand in a single sitting.
What Aggregateless Means in Practice
Aggregateless simply means I do not keep a big “User” or “Order” object cluster in memory, containing all the business rules and structure. When a command arrives, I ask the store only for the events that matter to that command, build the tiny bit of state of what is specifically needed in the context of the command, and throw that state away once the decision is made.
Each feature slice works the same way. They all query the event store using a filter to rebuild their own view from scratch.
Consistency is handled inside the command context itself. The command carries a filter that describes its context. In the feature slice, we read the context, decide what new events are needed, and then try to write them back with the very same filter. PostgreSQL makes the write succeed only if nothing in that context has changed. If it has, I retry or tell the caller to try later.
The decision code is pure functions: given past events and a command, return new events or an error. That purity keeps tests straightforward, I feed in events and check the result.
Functional Core / Imperative Shell in a Nutshell
The pattern is simple.
- Functional core – Pure functions. They take a list of past events plus the incoming command and return either new events or an error. No database calls, no timestamps from the outside, no hidden state. Give the same input, get the same output.
- Imperative shell – This is the part that handles all input and output. It loads the context from a database, an API, or any other source, passes the relevant data to the functional core, and, if a decision is made, tries to persist the computation results. The write is typically done in one atomic step, so if the context is still valid, the events are saved. If not, the operation fails.
Because the core is pure, unit tests run in milliseconds without a database. And because the shell is small, you can swap PostgreSQL for anything else that supports the same two operations: query by filter and append with a guard.
Read more here: https://ricofritzsche.me/simplify-succeed-replacing-layered-architectures-with-an-imperative-shell-and-functional-core/
Hands-On
I have already unpacked these ideas across several posts. If you missed them, feel free to catch up later. For now, let’s jump straight into the hands‑on part.
Setting Up PostgreSQL
If you don't have a local PostgreSQL instance running, you can bring one up like this:
docker run --name eventstore-pg \
-e POSTGRES_PASSWORD=postgres \
-p 5432:5432 -d postgres:17
Then create a .env file so the code knows where to connect:
echo "DATABASE_URL=postgres://postgres:postgres@localhost:5432/bank" > .env
If you're already running PostgreSQL elsewhere, just point the .env to that instance. Make sure your PostgreSQL user has permission to create the database and schema. That setup runs automatically on first use when you run one of the examples in the repo.
No extra setup is needed. When you run store.migrate() it creates everything:
- A single events table
- GIN and B-tree indexes for fast lookups
- Nothing per event type
Here’s what the table looks like:
CREATE TABLE events (
sequence_number BIGSERIAL PRIMARY KEY,
occurred_at TIMESTAMPTZ NOT NULL DEFAULT now(),
event_type TEXT NOT NULL,
payload JSONB NOT NULL,
metadata JSONB NOT NULL DEFAULT '{}'
);
Each row is a fact. The payload holds the full event data, event_type tells us what kind it is and metadata can track tracing info, source system, user ID, whatever you need later. No separate schema per event type. No table per aggregate. Just one simple table that holds every event. This is flexible enough to handle anything the system needs.
Query Filters
A command decides what data it needs by building an EventFilter. The filter names event types and, if needed, key‑value checks inside the JSON payload.
// Find all deposits for a given account
const filter = EventFilter
.createFilter(['MoneyDeposited'])
.withPayloadPredicate('accountId', accountId);
The same filter goes back into append when you write new events. This is important, because that single reuse is the trick: it asks the database to ensure the view you read is still the view you write against.
await store.append(filter, newEvents, maxSequenceNumber);
There are no shared entities and no global version numbers involved. The only thing that defines the context for a command is the filter it provides.
Optimistic Locking with a CTE
One question keeps coming up:
How does this work without version numbers or locking rows?
The answer is simple. To guarantee consistency during concurrent operations, the event store relies on optimistic locking. Rather than locking rows or maintaining explicit version numbers, it uses a Common Table Expression (CTE) to ensure that new events are only inserted if the original context remains unchanged.
Here’s the core idea:
WITH context AS (
SELECT MAX(sequence_number) AS max_seq
FROM events
WHERE ${contextCondition}
)
INSERT INTO events (event_type, payload, metadata)
SELECT unnest($${eventTypesParam}::text[]), unnest($${payloadsParam}::jsonb[]), unnest($${metadataParam}::jsonb[])
FROM context
WHERE COALESCE(max_seq, 0) = $${expectedMaxSeqParam}
Here’s what happens step by step:
- First, the ctx block checks which events matched the filter when we loaded the context. It stores the latest sequence_number it finds.
- Then the INSERT only runs if that number is still the same.
- If another writer has added a matching event since then, the number will have changed and the INSERT will fail silently. This is our signal that the context is no longer valid.
This gives us strong consistency without any locks or version columns. Nothing is blocked. Multiple writers can act in parallel, and if the context shifts underneath, the write is rejected. The whole check happens inside one atomic SQL statement.
Here's the full flow, from command to final write:
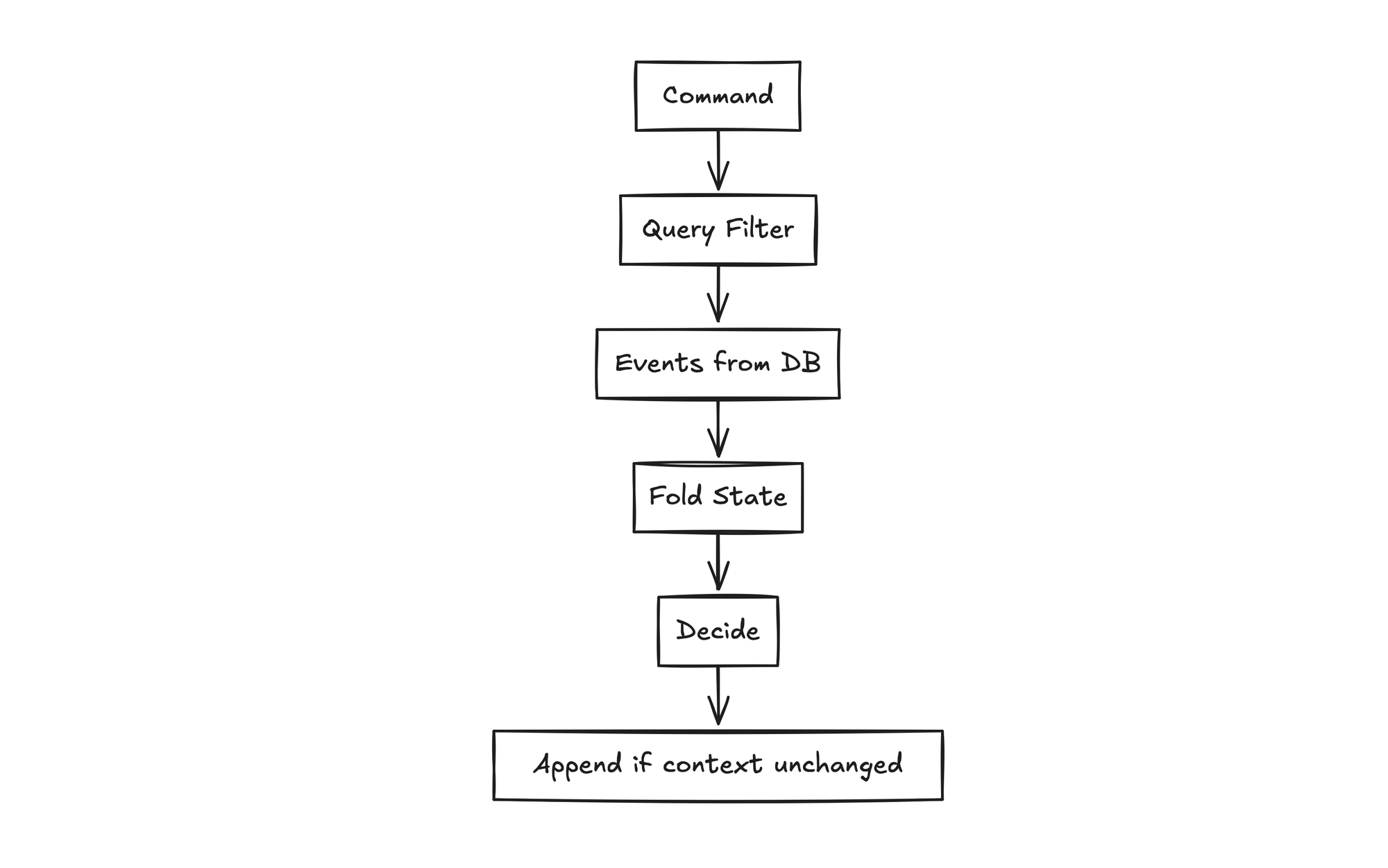
Let’s now look at how this maps to real TypeScript code.
The EventStore in TypeScript (Code Walkthrough)
The full implementation is available in this repo, but here is a quick walkthrough of the core parts.
At the center of the system are two Event Store operations:
- Load events based on a filter (query)
- Append new events, but only if the context has not changed (append)
Everything else builds around that.
Defining Events
Each event is just a plain object that knows how to describe itself. It must implement a small interface:
export interface HasEventType {
eventType(): string;
eventVersion?(): string;
}
An example event might look like this:
class BankAccountOpened implements HasEventType {
constructor(
public readonly accountId: string,
public readonly customerName: string,
public readonly accountType: string,
public readonly initialDeposit: number,
public readonly currency: string,
public readonly openedAt: Date = new Date()
) {}
eventType(): string {
return 'BankAccountOpened';
}
eventVersion(): string {
return '1.0';
}
}
There are no base classes and no inheritance trees. Just clear data with a type.
Building a Filter
A command starts by declaring what it needs from the event store. This is done using an EventFilter, which specifies the event types and optional payload fields.
const filter = EventFilter.createFilter(
['BankAccountOpened', 'MoneyDeposited', 'MoneyWithdrawn', 'MoneyTransferred'],
[
{ accountId: fromAccountId },
{ accountId: toAccountId },
{ toAccountId: fromAccountId },
{ fromAccountId: toAccountId }
]
);
This filter does two things: it defines what context to load for the decision logic, and it becomes the guard condition when trying to append new events. That reuse is what keeps everything consistent.
The Store Interface
The store itself exposes a minimal interface:
export interface QueryResult<T extends HasEventType> {
events: T[];
maxSequenceNumber: number;
}
export interface IEventStore {
query<T extends HasEventType>(filter: EventFilter): Promise<QueryResult<T>>;
append<T extends HasEventType>(filter: EventFilter, events: T[], expectedMaxSequence: number): Promise<void>;
close(): Promise<void>;
}
The query function loads all events that match the given filter. The append function tries to write new events, but only if the same filter still matches the same context. If something has changed in between, the write fails silently.
This interface is storage-agnostic. While the example here uses PostgreSQL, the same pattern works with any backend that supports filtered reads and guarded writes. You could implement it using MongoDB, DynamoDB, or even a file-based store, as long as you can enforce the condition that new events are only written if the original context is still valid.
A Closer Look at the PostgreSQL Implementation
The PostgreSQL store is built around the two core operations: query and append. It follows the IEventStore interface exactly, and all logic sits in a single class: PostgresEventStore.
Here’s a simplified look at how the query and append parts work:
async query<T extends HasEventType>(filter: EventFilter): Promise<T[]> {
const query = `
SELECT * FROM events
WHERE event_type = ANY($1)
AND payload @> $2
ORDER BY sequence_number ASC
`;
const result = await this.pool.query(query, [filter.eventTypes, filter.payloadPredicates]);
return result.rows.map(row => this.deserializeEvent<T>(row));
}
This loads all matching events for the context a command is interested in. It’s fully filter-based.
Appending new events (with consistency check):
async append<T extends HasEventType>(
filter: EventFilter,
events: T[],
expectedMaxSequence: number
): Promise<void> {
const eventTypes = events.map(e => e.eventType());
const payloads = events.map(e => JSON.stringify(e));
const metadata = events.map(e => JSON.stringify({ version: e.eventVersion?.() || '1.0' }));
const contextQuery = this.buildContextQuery(filter);
const insertQuery = this.buildCteInsertQuery(filter, expectedMaxSequence);
const params = [
...contextQuery.params, // context filter
expectedMaxSequence, // value from query time
eventTypes, // values to insert
payloads,
metadata
];
const result = await this.pool.query(insertQuery, params);
if (result.rowCount === 0) {
throw new Error('Context changed: events were modified between query and append');
}
}
Notice that expectedMaxSequence is passed in from the calling code. This value must come from the original query() step. The append() function does not re-read the context. It trusts the caller to provide the sequence number that reflects what they saw.
The actual insert is guarded by a CTE that re-evaluates the same filter and only proceeds if the sequence number hasn’t changed. That is optimistic locking, scoped to exactly what the command cares about.
This approach guarantees consistency without global versioning or stream-based locking. And since the boundary is defined by the filter, it is visible, testable, and flexible.
No Extra Abstractions
The code stays close to the problem. There are no decorators, no framework hooks, and no code generation involved. The store is just a small adapter over PostgreSQL that does exactly what you ask: read events, check context, write facts.
That simplicity is what makes it easy to reason about. Every line of logic is visible. Every piece of state comes from events. There is no global registry needed. There is no hidden coupling, and nothing to configure. Just data, filters, and pure functions.
Pure Business Logic Example
Let’s look at how the decision logic works. This is the part that folds the current state from events and evaluates the command. It does not talk to the database, it does not know anything about filters or storage, and it has no side effects. It is just a plain function that takes input and returns either new events or an error.
Here’s an example from the banking use case: opening a new account.
First, we define the shape of the state we want to fold:
type AccountState = {
exists: boolean;
};
Then, we build that state by folding past events:
function foldAccountState(events: BankAccountOpened[]): AccountState {
return { exists: events.length > 0 };
}
It doesn’t get much simpler. If we find at least one BankAccountOpened event, the account exists.
Next comes the decision logic. It takes the folded state and the command and decides whether we are allowed to proceed:
function decideOpenAccount(
state: AccountState,
command: OpenBankAccountCommand
): Result<BankAccountOpened, OpenAccountError> {
if (state.exists) {
return {
success: false,
error: { type: 'AlreadyExists', message: 'Account already opened' }
};
}
const event = new BankAccountOpened(
command.accountId,
command.customerName,
command.accountType || 'checking',
command.initialDeposit || 0,
command.currency || 'USD'
);
return {
success: true,
event
};
}
This function is easy to read and easy to test. If the account already exists, we return an error. Otherwise, we emit one event that captures everything needed to describe what just happened.
There are no external dependencies. Even the timestamp is part of the event constructor, so the logic stays free of global state.
This separation makes testing straightforward. I can write unit tests that feed in a list of past events and a command, then check if the result is what I expect. There’s no setup, no mocks, and nothing to clean up afterward.
This is what functional core means in practice: a function that sees everything it needs and nothing else. No framework required.
Running the Examples
To see the full flow in action, the repo includes a simple CLI with a set of step-by-step examples. These examples show how commands are handled, events are written, and state is rebuilt, without you needing to wire anything yourself.
Start by installing the dependencies:
npm install
Then run the examples and try it out:
npm run cli
This will guide you through a few typical operations: opening an account, depositing money, and checking the current balance. Everything runs against the real PostgreSQL instance and uses the event store exactly as described above.
Once the CLI is running, you can walk through common actions like opening an account, depositing money, and checking balances. Each operation runs through the real event store, talks to PostgreSQL, and stores facts in the events table, just like in production.
You can inspect the table at any point to see the raw events. Since everything is stored as JSONB, it’s easy to query and debug directly.
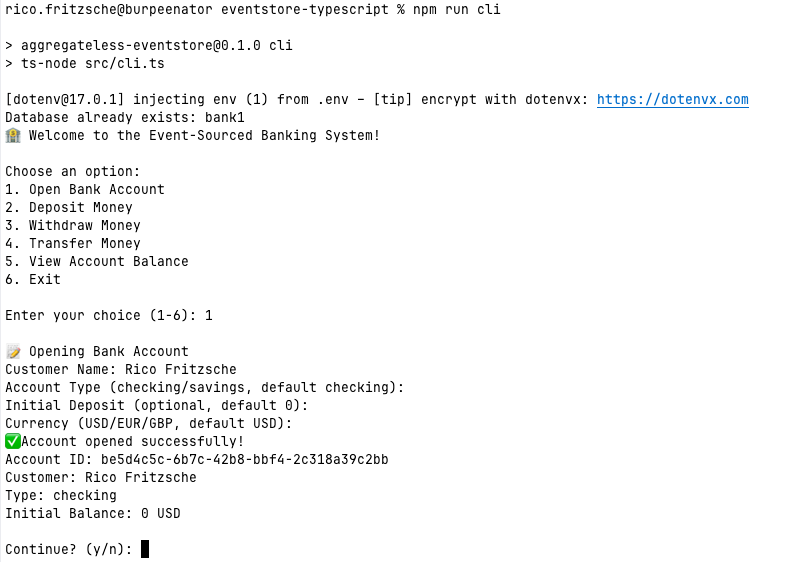
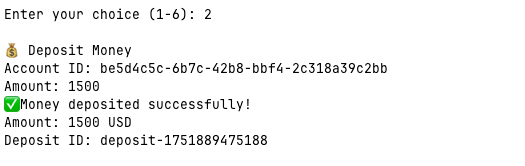
Let's add some money...
Let's check the events table in the PostgreSQL database.

After adding another amount, lets simply check the balance.
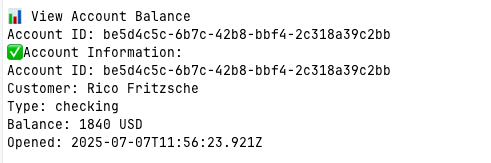
You’ll find the CLI in the src/cli.ts file. It’s self-contained and easy to extend.
Testing for Confidence
The system is split cleanly into two layers, and that makes testing straightforward.
The functional core contains all the decision logic. These are just pure functions. You can pass in a list of events and a command, and check the result. That’s it. There is no database involved, no mocks, and no setup or tear-down. These tests run fast and tell you exactly where your logic breaks.
The imperative shell is the part that talks to the event store. Here you’ll want integration tests. These load a real PostgreSQL database, send commands through the full pipeline, and verify that the events were written correctly. Since the store is just PostgreSQL under the hood, this kind of testing is simple and reliable.
You don’t need a mocking framework. You don’t need test doubles. The separation makes everything easier to isolate and reason about.
Conclusion
The event store is designed to stay simple in structure, yet fully capable of supporting large systems and high load. It gives you the control you need today, and the flexibility to scale as your system grows.
If your event volume increases, you can batch inserts, index more fields, or add simple partitioning on the database level. PostgreSQL scales well for this kind of workload, especially when events are stored as JSONB and indexed properly.
If needed, you can later add a tags field to your events, similar to how the DCB approach works. In my experience, filtering on JSONB alone is fast and flexible, even at scale. But tags can help when you want to optimize query performance. Nothing in this setup prevents that.
And if you decide to re-implement this in Rust, Go, or Python, it works the same way. The idea is not tied to TypeScript. All you need is a way to load events by filter, make a decision, and try to append with the same guard.
This approach is simple, but powerful. It avoids the usual complexity that comes with aggregates, shared states, and framework rules. Instead, it gives you clear boundaries, stable behavior, and full control over how decisions are made.
You work with real events. You define context through filters. You decide through pure functions. You store facts, not state.
If you want to dive into the code, here’s the repo: github.com/ricofritzsche/eventstore-ts-example
Cheers!
Note: A few of the questions I've received about projections, streaming from the event store, and partitioning strategies deserve more space. I’ll cover those in upcoming articles. I'll show how I use PostgreSQL to stream events into read models, how tenant-level partitioning works in practice, and how to keep projections fast and isolated without turning everything into infrastructure overhead. Stay tuned.