Beyond Aggregates: Lean, Functional Event Sourcing
Why I Moved Beyond Aggregates to Functional Domain Modeling

Event sourcing naturally aligns with functional programming principles. Why do I call it a functional programming principle? Because, it’s all about immutability. Once an event is recorded, it’s set in stone. It's a fact that can’t be altered.
I’ve built systems myself following the tactical patterns as defined by Eric Evans in Domain-Driven Design and elaborated in the “Red Book” by Vaughn Vernon. These concepts are object-oriented constructs that combine data (state) and behavior (methods) to enforce business rules. They leaned heavily on indirection.
The real goal is to design systems that remain clear, flexible and comprehensible, even when they are highly complex.
What I call “object-oriented” here. I’m referring to the mainstream, state-plus-behaviour style popularized in enterprise Java/C# (big mutable objects that carry both data and methods) not Alan Kay’s original message-passing definition. The article pushes back on that specific flavor, not on objects or encapsulation in general. (Read this twice!)
Beyond CRUD and Object-Models
I get that many developers and teams stick to traditional relational data structures. Shifting to event-based thinking is a big mental leap. Most teams still think in CRUD and big object-models. Last year, I joined a logistics project late in the game, and the first thing that hit me was the focus on CRUD APIs and relational models. The actual data flow and processing? Barely mentioned.
The push-back against event sourcing usually comes from seeing it buried under aggregate-heavy, object-oriented CQRS frameworks and endless arguments about which event store is “best.” My advice: skip the frameworks. Lightweight, expressive functions are all you need.
Remember, CQRS is just Bertrand Meyer’s Command–Query Separation: a routine either changes state or returns data but never both. Layered designs such as Clean or Onion flip that on its head by slicing code along technical layers (entities, use cases, interfaces, infrastructure). Read and write logic end up side by side, muddying intent and locking you into rigid, horizontal stacks. Teams that try “vertical slices” often carry that baggage with them, so commands and queries still live in the same layers.
However, this article isn’t about tearing down Clean Architecture’s flaws. It’s about event sourcing as the heart of behavior-driven software development. When Greg Young introduced CQRS, he used a killer real-world example: banking. It shows why event sourcing isn’t more common. Everyone gets that storing just the final balance of a bank account would be absurd. Imagine going to a bank, saying something’s off with your account, and the teller shrugging, “I can only see your current balance, not the transactions that got you there.” That’d be a disaster. Yet, in many business applications, we accept this approach.
My goal with this article is to show that event sourcing doesn’t have to be complex. Quite the opposite. It’s all about how you approach it.
What you won’t find here:
- CRUD Repositories
- Mainstream/Enterprise object-oriented principles
- Frameworks trying to solve the problem generically
What you will find:
- Expressive code
- Pure functions
- I/O via imperative shell
- Event-sourced architecture as a functional programming principle
- A clear, feature sliced functional CQRS example
Modeling with Pure Functions and Immutable Events
A functional domain model comprises pure functions and immutable types. As the best parts of Domain-Driven Design teach us, it should be expressed in a language everyone on the project understands.
For me, the core idea of an event-sourced architecture is simple: capture everything that happens in the system as immutable facts (events). No sophisticated framework is required, and you don’t need the stateful, over-engineered “aggregates” from DDD’s tactical design. It only adds needless complexity.

Each command is fed into a pure, deterministic function that always returns an immutable event. I will explain the I/O issues later in this article.
Typical DDD aggregates as described in the "blue" and "red" DDD books bundle data and behavior into heavy object entity models, complete with repositories and layers of indirection. That pollution drags infrastructure concerns into your domain, tangling pure logic with I/O and interfaces. From my years building complex systems, I can say with confidence: object-oriented aggregates don’t tame complexity. They create it!
Why I Avoid DDD Aggregates
There’s a good reason I steer clear of the DDD term “aggregate” and its underlying concept, opting instead for a functional view of domain modeling. It simply doesn’t play well with fully self-contained feature slices. The issue comes up often when discussing Vertical Slice Architecture, especially among those stuck in an object-oriented mindset: where do you put the entities (an object model made up of nested objects and data structures)? If multiple feature slices rely on the same entity, they lose their independence. Alternatively, if one slice owns the entity, it ends up juggling multiple responsibilities, which defeats the purpose of slicing.
Take a “Bank Account” as an example. In an object-oriented DDD approach, this entity would own all related operations, like depositing or withdrawing money, along with the state (e.g., balance) and rules (e.g., no negative balances). These operations are tightly bound to the entity, so you can’t split them into independent slices without creating problems. Either both the “Deposit Money” and “Withdraw Money” slices depend on the same entity, breaking their autonomy, or you cram both operations into a single slice, making it do too much. The object-oriented workaround is to centralize the entity and its logic in a shared model or service, leaving slices with just endpoints. That’s not slicing. It’s just a rehash of layered architecture with thin veneers.
Let's try to solve this cleanly. Each slice (say, “Deposit Money” or “Withdraw Money”) operates on the same event stream for the bank account, which contains all events like MoneyDeposited and MoneyWithdrawn. To reconstruct the account’s state (e.g., the balance), a slice folds the stream’s events using pure functions. But the logic is fully separated: the “Deposit Money” slice handles deposit commands and generates MoneyDeposited events, while the “Withdraw Money” slice processes withdraw commands and produces MoneyWithdrawn events. This keeps slices independent, each focused on its own feature, without the object-oriented tangle of an aggregate which usually encapsulates data and behavior.
That’s why I see event sourcing as a functional principle: it lets slices stay autonomous while sharing a single source of truth: the event stream.
A Practical Example: Depositing Money with Functional Event Sourcing
To bring event sourcing to life, let’s dive into the deposit_money feature from a bank account example I built in Rust. This example shows how functional event sourcing can make feature slices truly self-contained, keeping everything (state, folding, and logic) right where it belongs. No centralized domain models, no object-oriented baggage, just pure functions and immutable events. I’ll walk through the code, zoom in on the “fold” concept for state reconstruction, and show why this approach beats the complexity of traditional designs.
This functional event sourcing example in Rust shows precisely how a command → pure function → event flow works in an event-sourced architecture.
use uuid::Uuid;
use sqlx::{FromRow, Pool, Postgres, Transaction};
use crate::infrastructure::{
db::PostgresError,
storage::{append_event, load_events},
};
use crate::events::{AccountEvent, AccountEventTrait};
fn default_version() -> String {
"1.0".into()
}
#[derive(Debug, thiserror::Error)]
pub enum ExecuteError {
#[error(transparent)]
Domain(#[from] DepositError),
#[error(transparent)]
Infrastructure(#[from] PostgresError),
}
#[derive(Debug, Clone, PartialEq)]
pub struct AccountState {
pub exists: bool,
}
pub fn fold_state(events: &[AccountEvent]) -> AccountState {
AccountState {
exists: events.iter().any(|e| matches!(e, AccountEvent::AccountCreated { .. })),
}
}
#[derive(Debug, Clone, FromRow)]
pub struct DepositMoney {
pub account_id: Uuid,
pub amount: f64,
}
#[derive(Debug, thiserror::Error, PartialEq)]
pub enum DepositError {
#[error("Account does not exist")]
AccountNotFound,
#[error("Amount must be positive")]
NegativeOrZeroAmount,
}
pub fn process_command(
state: &AccountState,
cmd: &DepositMoney,
) -> Result<Vec<AccountEvent>, DepositError> {
if !state.exists {
return Err(DepositError::AccountNotFound);
}
if cmd.amount <= 0.0 {
return Err(DepositError::NegativeOrZeroAmount);
}
Ok(vec![AccountEvent::MoneyDeposited {
account_id: cmd.account_id,
amount: cmd.amount,
version: default_version(),
}])
}
This code powers the deposit_money slice, a self-contained module that handles everything needed to deposit money into a bank account. It’s a good example of how to keep domain logic pure and independent, with no reliance on shared models or infrastructure creeping in. Let’s break it down:
- The MoneyDeposited event is defined in a minimal shared events module and captures the fact of a deposit with an account ID and amount. As functional programming demands, it is immutable and is part of the AccountEvent enum that is shared as a contract.
- The State (AccountState) is a simple structure containing only an 'exists' flag, since deposits only need to know if the account already exists. It is owned by the slice rather than a centralized domain model.
- fold_state is a pure function that reconstructs the AccountState by checking whether an AccountCreated event exists in the stream. It is lightweight and local to the slice, thus avoiding shared folding logic. For deposits, we only care about existence, not balance.
- The function validates the deposit command (i.e. that the account exists and the amount is positive) using a domain-specific DepositError. This keeps the core pure and free from infrastructure such as PostgresError, which remains in the shell.
- The imperative shell (fn execute) ties the core to the infrastructure. It loads the event stream, converts it to determine the state, processes the command and adds events in a transactional manner, mapping domain errors to infrastructure errors as required.
// Imperative Shell
pub async fn execute(
pool: &Pool<sqlx::Postgres>,
command: DepositMoney,
) -> Result<(), ExecuteError> {
let past = load_events(pool, command.account_id)
.await
.map_err(ExecuteError::Infrastructure)?;
let state = fold_state(&past);
let new_events = process_command(&state, &command)
.map_err(ExecuteError::Domain)?;
let mut tx: Transaction<'_, Postgres> =
pool.begin().await.map_err(PostgresError::Sqlx)?;
for ev in &new_events {
tx = append_event(tx, command.account_id, ev, ev.event_type())
.await
.map_err(ExecuteError::Infrastructure)?;
}
tx.commit().await.map_err(PostgresError::Sqlx)?;
Ok(())
}The code above represents the imperative shell. It is an outer layer that performs side-effects (DB calls, HTTP, etc), then hands pure data to the functional core and persists the events it gets back. State and I/O can’t be wished away, so the model is functional core + imperative shell: pure functions in the center, side-effects pushed to the outer rim.
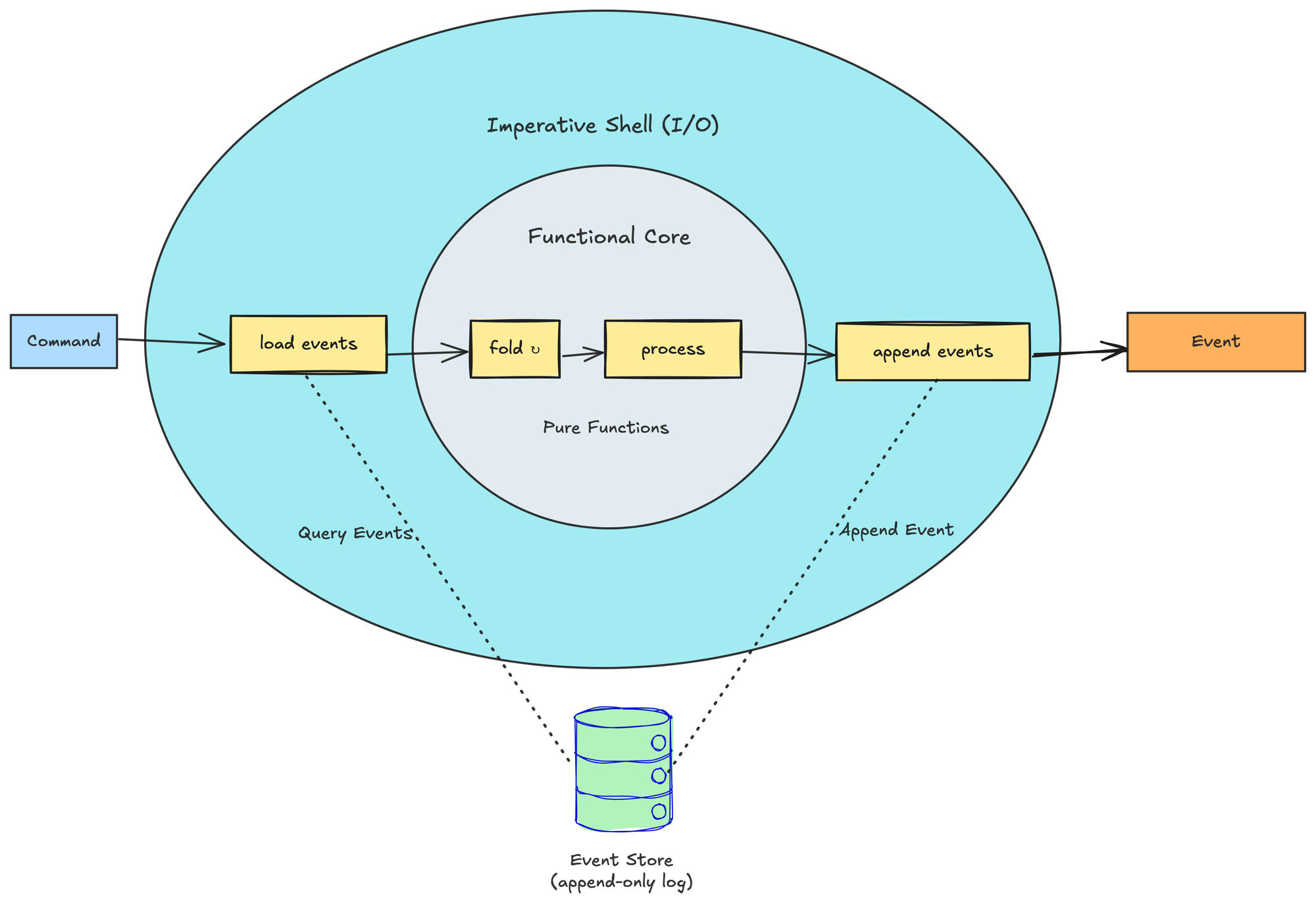
A command enters the shell, which loads past events, hands them to pure functions (fold -> process/decide), and then appends the new events back to the event store.
External reads (I/O). Any data that isn’t in the stream, i.e. credit limits, holiday calendars, FX rates, etc., is fetched in the imperative shell before the pure core runs and is passed in as plain values. This keeps the core referential transparent while still solving real-world look-ups.
About the Repository pattern. load_events and append_event are the repository here, but reduced to two explicit I/O functions in the shell. So yes, conceptually we do have a repository in the Fowler/Evans sense: there is still a boundary where domain state is re-hydrated and persisted atomically. But the difference is that I chose to expose that boundary as two very small, explicit I/O functions instead of a collection-like interface that returns rich objects.
Optimistic concurrency. Each append_events call runs in a single DB transaction. The composite primary key (account_id, seq_no) makes concurrent inserts collide; the duplicate-key error is surfaced as ConcurrencyConflict → HTTP 409. (The seq_no is simply SELECT COALESCE(MAX(seq_no),0)+1 for that account, good enough for the demo, swap in an expected_version check for production.)
CREATE TABLE account_events (
id UUID PRIMARY KEY,
account_id UUID NOT NULL,
event_type VARCHAR NOT NULL,
payload JSONB NOT NULL,
sequence_number BIGINT NOT NULL, -- stream offset
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
CONSTRAINT unique_account_sequence UNIQUE (account_id, sequence_number)
);
Note on aggregates. AccountState is the aggregate/consistency boundary: every command folds the event stream for that AccountId and decides from there. What changes is the shape. Each vertical slice reconstructs only the fields it needs, so no monolithic BankAccount object graph travels through the codebase.
Note: If you never heard about the concept of Functional Core/Imperative Shell (FCIS) I recommend to read this article:

The Power of Folding
In the deposit_money feature, the fold_state process is straightforward: it scans the AccountEvent stream to see if an AccountCreated event exists, setting state.exists to true if found.
For a stream such as [AccountCreated, MoneyDeposited(100), MoneyWithdrawn(30)], folding yields an AccountState with exists set to true. The process is pure and predictable, and is owned by the feature slice, no shared folding module is needed.

Compare this to the withdraw_money slice, which requires both existence and balance checks. Its fold_state function processes all events AccountCreated sets exists to true, MoneyDeposited adds to the balance and MoneyWithdrawn subtracts yielding AccountState:
{ exists: true, balance: 70.0 }Each slice tailors its folding to its needs, keeping logic local and focused. This is what makes slices truly self-contained: they own their state reconstruction rather than relying on a centralized object model to dictate how events are applied.
This approach strikes the right balance between autonomy and simplicity. The deposit_money slice owns its own folding, state and error logic. The only shared element is the 'AccountEvent' enum, which is a minimal contract and not an object model. By keeping fold state local, we avoid the anti-pattern of centralized logic, allowing each slice to decide how to interpret the event stream. The approach is functional to the core, with pure functions, immutable events and no infrastructure leaking into the domain.
Contrast this with an object-oriented DDD setup, where a BankAccount entity would bundle all the logic, forcing the slices to depend on it or become bloated with multiple tasks. Here, folding is expressive because you can see exactly how deposit_money checks account existence, nothing more, nothing less. There are no aggregates, no repositories and no indirection. There is just a self-contained slice doing its own thing, backed by a shared event stream that keeps everything consistent. This is why I prefer functional event sourcing for building systems that are easy to understand, even at scale.
Deterministic Tests - No Mocks, No Maybes
Functional event sourcing turns testing from a chore into a two‑line assert. Because the core is nothing but pure functions, you hand it input, collect the output, and you’re done.
No fake databases, no DI contortions, no side effects.
#[cfg(test)]
mod tests {
use super::*;
use uuid::Uuid;
#[test]
fn process_command_success() {
let id = Uuid::new_v4();
let state = AccountState { exists: true };
let cmd = DepositMoney { account_id: id, amount: 42.0 };
let evs = process_command(&state, &cmd).expect("should succeed");
assert_eq!(evs.len(), 1);
if let AccountEvent::MoneyDeposited { account_id, amount, version, .. } = &evs[0] {
assert_eq!(*account_id, id);
assert_eq!(*amount, 42.0);
assert_eq!(version, "1.0");
} else {
panic!("unexpected event");
}
}
}
One input, one expectation. The test is repeatable, instantaneous, and survives refactors because it speaks the domain’s language: deposit money, get a MoneyDeposited fact. The shell (database, transactions, I/O) is tested separately with thin integration tests; the core stays pure and extremely fast. That’s confidence without the mocking circus.
Conclusion
Event sourcing is older than software. Accountants, doctors, and lawyers have always kept an “append-only ledger” so nothing gets lost in translation, or in history.
What matters to us as developers is the translation of that timeless idea into code.
Functional fit, not dogma!
Recording immutable facts and replaying them with a fold lines up perfectly with pure functions and immutability, but that doesn’t mean the whole codebase must be pure FP. Keep the core referentially transparent; let the shell do the I/O.
The goal isn’t to enforce a new dogma; it’s to keep the original elegance of the ledger while writing code that is easy to reason about, test, and evolve. Strip away the over-engineering, keep the ledger, and let the rest be just enough plumbing to ship. Finally, we should now focus on flexibility with regards to requirements.
The good thing is you don’t need a framework for CQRS/ES; keep the plumbing thin so all these trade-offs stay visible.
Take a look at the complete Bank Account example, including the fold logic, process_command and execute shell functions, as well as a full suite of deterministic unit tests, all of which are available on GitHub.
View the full Rust example and tests on my GitHub.
Cheers!