Bounded Contexts: Behavior Over Data Structures - Part II
How to Use Aggregates to Modularize Software Systems.
In part one of this series, I talked about the importance of understanding Bounded Context when modeling software systems. This is a big deal because it clusters and makes large domains easier to understand. To be clear, it means that you have to figure out the subdomains within a large business domain before you can identifying Bounded Contexts. They define clear boundaries around a subdomain, each with its own model, language, and rules.
I really focused on "verbs," to make a point. I did this on purpose because I've seen too many systems built around static things, or "nouns," and then try to add behavior later. It's important to remember that you need both the "nouns" and the "verbs" they do to fully explain what's going on. Both are super important to writing good software. It's not black or white! We need a good balance.
...both the nouns and verbs are required to fully describe behavior. Just as OOP is often misused, so is DDD. Both are important for building good software. Our profession seems to wander between extremes instead of seeking balance. - Dick Dowdell on Medium
Today I want to go deeper in another fantastic key concept for modularization in DDD: Aggregates
So, after we've figured out the Bounded Contexts, we've basically pinpointed the modules we can use to break a big, bulky system into more manageable pieces. These could be the building blocks for turning a monolith into a set of modules, or even microservices or self-contained systems. But it's kind of a first guess - sometimes we might find that one of these contexts is actually too big and needs to be broken into smaller ones.
Now let's dive into tactical design and get closer to the actual coding. Everything we're discussing will be turned into code. We're always working within a Bounded Context, which could be a module in a monolith or a microservice. DDD introduces several patterns for tactical design, such as factories, repositories, value objects, entities, and Aggregates. We'll focus on value objects, entities, and Aggregates because they are critical to making things modular.
Entities stand out in DDD because they always retain their identity, behavior, and have their own life cycle. They are identified by their unique identity. It's this identity that distinguishes them from one another, even if they have identical attributes such as name, age, or job. Think of two people who may have the same name, age, and job. What really makes them different is their unique identity, not just the name or job title they may have.
An important point here: Entities in DDD are not data models (aka representations of db tables), they are domain models. They represent business objects with behavior. We are modeling domain concerns, not database tables.
Value objects are different. They don't have an identity or a life cycle. They're defined solely by their attributes and are always immutable.
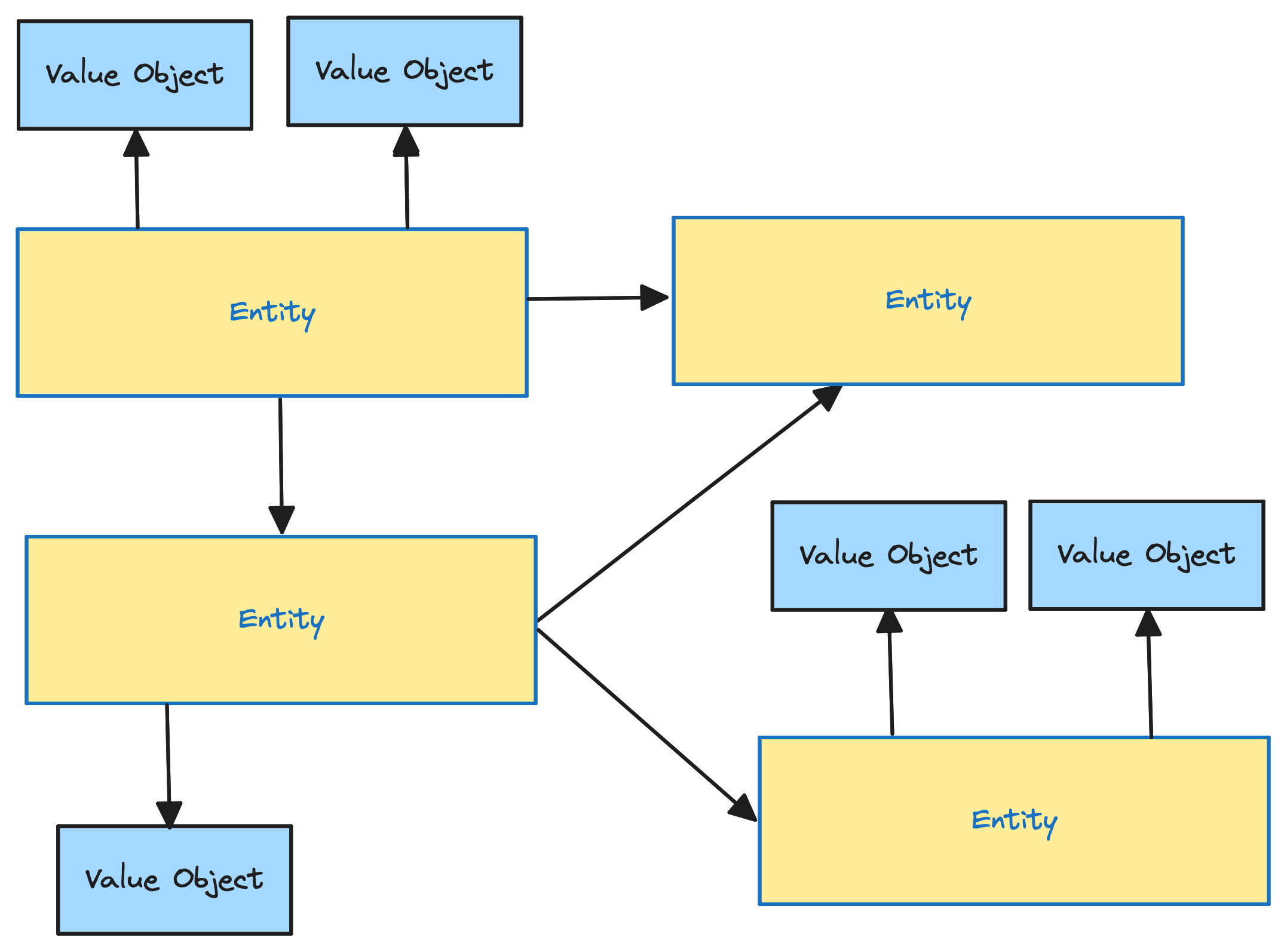
Aggregates are an excellent way to avoid large object graphs in a Bounded Context. This would happen if we were dealing only with value objects and entities. Aggregates are therefore useful for clustering value objects and entities and to define a boundary.
Without Aggregates, our object setups would quickly get too complicated and hard to follow, making them more likely to mess up. We don't want a change in one place accidentally causing problems somewhere else.
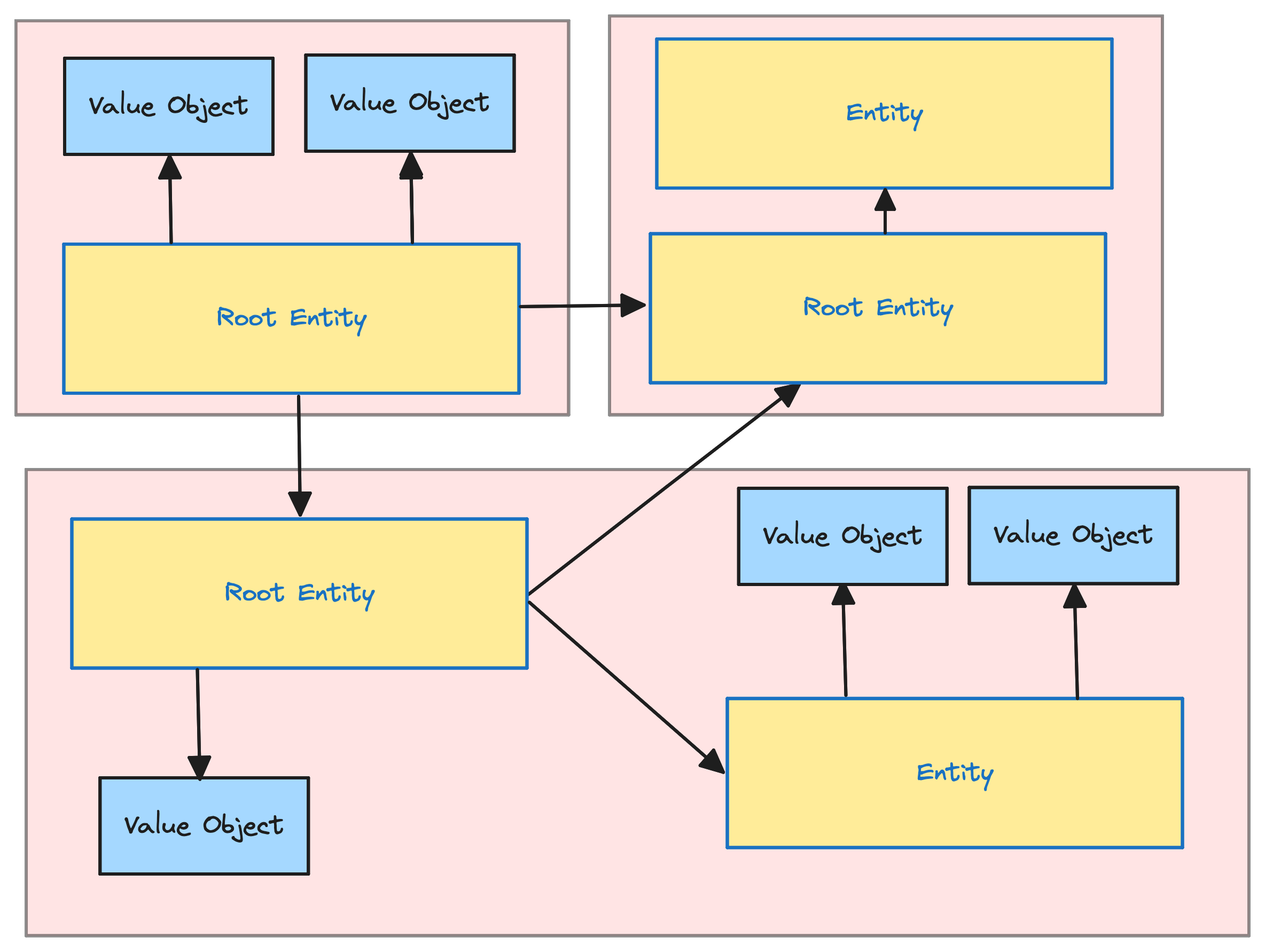
Like I mentioned before, we put entities and value objects together into what's called an Aggregate.
Each Aggregate has a key component known as the root entity, or Aggregate root, which serves as the single entry point to the Aggregate. The root entity has a unique global identity and is responsible for checking invariants.
Invariants refer to the rules or conditions that must always be true for the Aggregate to be considered valid. These can be anything from ensuring that an account balance never drops below zero to ensuring that an order has at least one item before it can be processed. The Aggregate root takes on the role of enforcing these invariants, ensuring the integrity and consistency of the Aggregate's state. This also means that whenever changes are made to any part within the boundaries of the Aggregate, all of the invariants of the Aggregate must be satisfied. In a sense, you can think of the Aggregate as a boundary for transactions.
In the image below, I've taken an example from Eric Evans' book "Domain-Driven Design" to illustrate how the Aggregate controls access to the clustered objects solely through the Aggregate root.
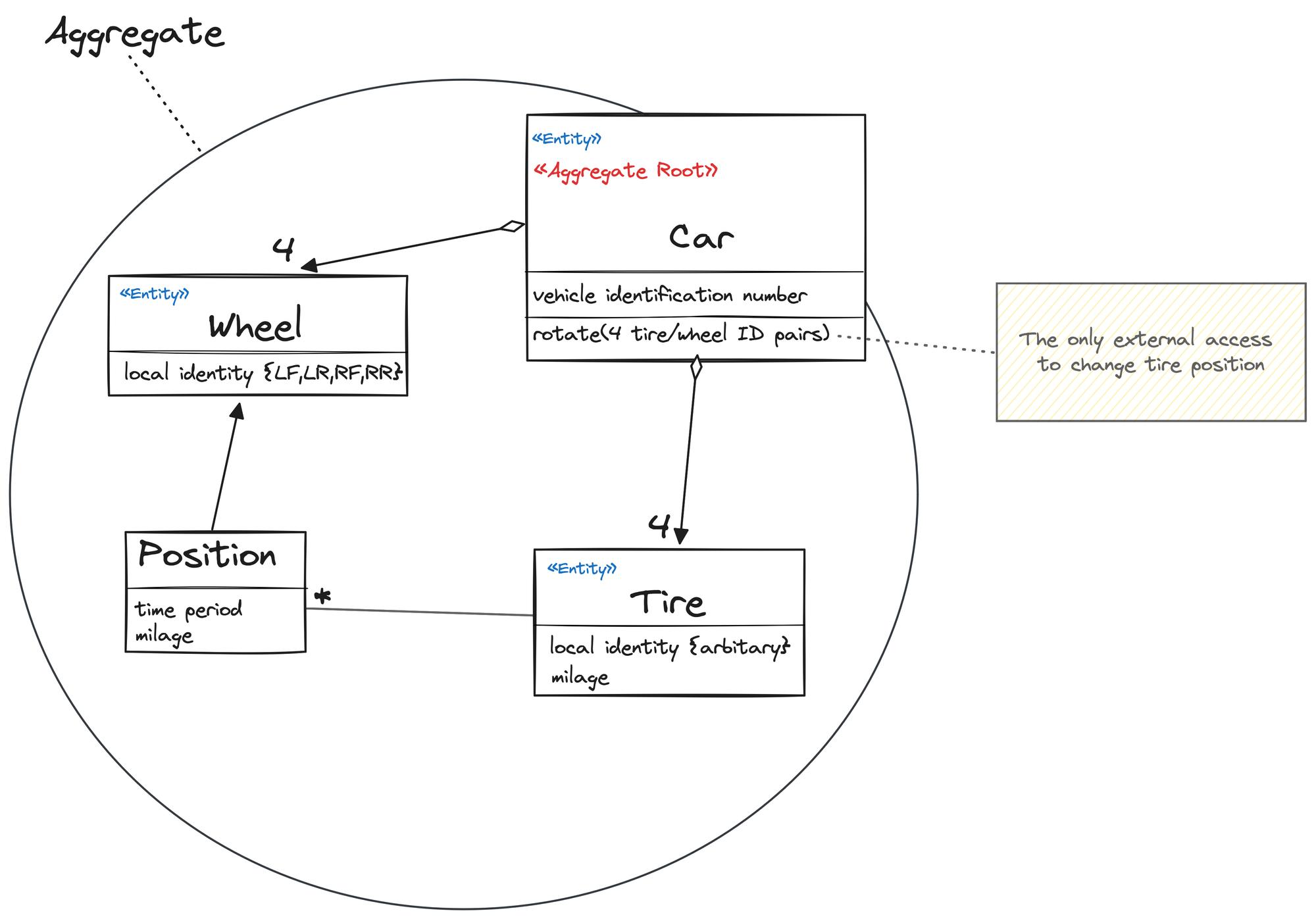
Other modules are not allowed to interact directly with the Tire entity. This rule is in place to maintain consistency throughout the system. It's important to understand that anything outside the boundary of the Aggregate cannot hold a reference to anything inside it, such as the Tire. The root can provide a copy of a value object to another object, but it doesn't keep track of what happens to that copy. Since it's just a value with no ongoing connection to the Aggregate, its fate outside the aggregate is inconsequential.
Aggregates should remain unaware of each other; they are independent units. They serve as a facade to hide the internal workings and specific business logic from anything outside their boundaries. However, it's acceptable for any object inside the aggregate to hold a reference, specifically the unique ID, to the root of another aggregate.
Cheers!
PS: Join me on my brand new Discord server if you want to discuss this article or other DDD-related topics in more detail.