Cutting Through the Noise: A Reflection on the True Essentials of Software Development
Escaping the Hype: The Art of Staying Focused on Value

Over the years, I’ve seen countless frameworks, patterns, best practices, and methodologies trend, peak, and fade away. Each claimed to be the definitive solution to our biggest challenges. But the real needs of software development have remained constant. At its core, software development isn’t about chasing the latest “must-have” technology. It’s about understanding the domain, delivering business value, and modeling solutions clearly and simply. This article explores how our industry’s obsession with hype can distract us from the real goal of solving problems effectively, and how I’ve come to appreciate simpler, more domain-focused approaches.
Separating Hype from Reality
Despite the continuous influx of new frameworks, architectural styles, and “revolutionary” methodologies, the underlying mission of software development stays the same: solve real problems.
While some new tools do deliver genuine efficiency or expressiveness, too many are driven by:
Buzzwords: Vague or superficial terms promising silver bullets.
Book Sellers: Experts, gurus, or influencers pushing a trademarked approach or methodology. Academies offering overpriced training courses and useless certificates.
Fear of Missing Out: The nagging worry that if you aren’t using this or that, you’ll be left behind.
This cycle can distract entire teams from focusing on value-driven and domain-oriented solutions. It’s essential to separate the genuinely useful from the merely fashionable.
Bounded Contexts: Clarity through Limits
I once went all in on Domain-Driven Design (DDD). I believed every project needed rich entities, value objects, and repositories. Over time, I realized that the real power of DDD is not in its tactical patterns. The strategic side is what keeps projects aligned with business goals. It sets the boundaries between services or modules and gives everyone a shared language. That shared understanding prevents confusion and wasted effort.
That big-picture thinking keeps teams from mixing unrelated concerns and stops them from building “just-in-case” structures.
Repositories, for instance, introduced extra layers for data access, so even simple queries involved multiple abstractions. Factories buried creation logic behind another layer that did not always match the real business needs. Instead of making the domain clearer, these patterns created a maze of indirection.
The main goal is to stay true to the business problem and avoid turning every detail into a tactical exercise.
Rethinking Rich Domain Models
I used to hate anemic domain models. I wanted every entity to carry all possible business rules, believing that would ensure “smart” code. In practice, these over-stuffed models turned into a liability. One small change triggered a chain reaction across many classes. Instead of moving forward with new features, teams often found themselves untangling side effects rather than delivering value. What I learned is that adding business logic to domain objects can be useful, but only when it truly expresses the domain. If it becomes a dumping ground for every rule or function, it muddles the flow of data and makes updates painful.
How Data Flows Through a System
In my opinion, a healthier approach is to focus on how data moves through each step of the system rather than stuffing all business logic and data into a single, bloated domain entity.
- Request Data – A client sends a message (command or a query).
- Processing – The server applies business rules, reads or updates the database, and prepares the output.
- Response Data – The server returns a response data to the client, this can be a representation of the data as a result of query or the processing status and minimal information in case of a command.
Each step gets its own data object, tailored to what’s happening. No need to force a so called rich model to handle everything, or settle for anemic shells with logic scattered elsewhere. Instead, a flow or message-driven approach creates distinct data objects for each stage, which keeps code understandable and aligned to what the system is actually doing at each moment.
Say you’re registering a user:
- Request Data: A RegistrationRequest record with email and password.
- Processing: Check the email’s unique, hash the password, save the user.
- Response Data: A RegistrationResponse record with a success note and the user’s ID.

For instance, in C# or Java, I prefer using records instead of classes for these step-specific data structures. Records make immutability straightforward. Once they are instantiated, their values do not change. This immutability reduces side effects and bugs. It also clarifies how data flows: when a request comes in, you create a new record to capture the data; you process or transform that record (maybe returning a new record if something changes); you send back a response record when everything is done.
Rich vs. Anemic vs. Flow-Driven
- Rich Domain Models try to put most business rules and methods inside the same objects that store the data. This can work in some cases, but it risks over-complication if you cram every bit of logic into a single “catch-all” class.
- Anemic Domain Models do the opposite. They store data in bare-bones classes or structs, with almost no domain logic. These are easy to read but scatter business rules across the codebase or push them into large service classes. Data classes have public setters so that everyone can change data from the outside without business rules etc.
- Flow-Driven Models split data into focused objects or messages that reflect each step in the pipeline. Business logic and transformations still have their place, but they're attached at the relevant step, rather than bloating your domain objects. Each part of the system deals with data in the form that makes sense for that stage.
It’s about clarity: a command kicks things off, data shifts as needed, and the user gets what they asked for.
Event-Driven Doesn’t Mean Event-Sourcing
When moving beyond simple request/response scenarios, an event-driven approach can help. You might model events that describe important state changes or activities, then publish those events to other parts of the system. This makes it easier to compose features from smaller, independent services or modules. But being event-driven does not mean you must use event sourcing. You can store state in a database with standard tables, enforce transactions for consistency, and still notify other parts of your system when changes occur. You do not have to jump on the append-only event store hype if it does not fit your needs. By the way, it's just a new form of just-in-case culture to argue that you should have all events because you might need them at some point. It's similar to arguing that you need repositories because you might need to replace the underlying database technology at some point.
Balanced Design: Expressive, Not Excessive
A rich domain model can help when it reflects genuine domain concepts, but many projects make these models far too big. Not every rule belongs inside an entity. Not every operation needs its own class or factory. If you treat data flow as a series of transformations, you keep each step clear: a command triggers logic, data is updated or retrieved, and the user gets a response that matches what they asked for. You can attach business logic where it is relevant in a dedicated building block rather than swelling your entities into monsters.
In the end, a balanced approach is best. Keep your models expressive but not bloated. Represent data in the forms that make sense at each stage. Use events to notify or trigger additional processing if that adds clarity. Save your data in a consistent way that is easy to manage, without locking yourself into a pattern just because it sounds advanced. The point is to deliver value, not to build the most complicated domain model possible. If a smaller, more focused model solves the problem, that is the right choice.
Stop Hiding SQL: Why Transparency Matters
Hiding SQL behind Object-Relational Mappers (ORMs) has long been popular, and admittedly, there are scenarios where ORMs are beneficial. They can help teams quickly spin up small prototypes or simplify basic CRUD-heavy applications, especially where performance and query complexity are not primary concerns.
However, in my experience, ORMs often cause more trouble than they're worth in larger or more performance-sensitive applications. Initially, ORMs seemed convenient, automating tedious tasks like mapping queries and managing object persistence. But hidden queries soon turned into debugging nightmares, obscuring performance issues behind layers of abstraction.
SQL itself is a powerful, expressive, and universally understood language. Keeping queries visible fosters transparency, aiding optimization, collaboration, and troubleshooting. Direct SQL enables easier performance tuning, clearer debugging, and faster iteration.
Yet, there are scenarios where ORMs remain practical:
- Rapid Prototyping: Quickly bootstrapping applications when time-to-market matters more than long-term optimization.
- Simple CRUD Applications: Straightforward apps with minimal business logic where ORM’s automation is genuinely helpful rather than hindering clarity.
The key is mindful choice: use ORMs when their benefits clearly outweigh complexity, but embrace direct SQL to maintain control, transparency, and performance where it counts most.
Here an example how it makes code clear, expressive and simple:
public sealed class ViewAssetsQueryHandler(IDatabaseExecutor dbExecutor)
: IRequestHandler<ViewAssetsQuery, Result<IReadOnlyList<Asset>>>
{
public async Task<Result<IReadOnlyList<Asset>>> Handle(ViewAssetsQuery request, CancellationToken ct)
{
const string sql = """
SELECT a.id, a.name, a.description, a.attributes, da.device_id, a.is_retired
FROM tracking.assets AS a
LEFT JOIN tracking.device_assignments AS da
ON a.id = da.asset_id AND a.tenant_id = da.tenant_id AND da.end_time IS NULL
WHERE a.tenant_id = @TenantId
AND (@IncludeRetired OR is_retired = false)
""";
var result = await dbExecutor.QueryMultipleAsync<Asset>(
sql,
new { request.TenantId, request.IncludeRetired }
);
return result;
}
}
Balancing SQL and Business Logic
Some teams push business logic into the database through stored procedures or triggers. Others try to keep everything in application code. A direct SQL approach does not force either extreme. You can store data with well-crafted queries while still keeping domain rules in code. If a rule involves complex calculations or cross-service interactions, it probably belongs in dedicated building block. If it is a matter of simple validations, you can enforce them in the database if that adds clarity or efficiency.
Why SQL Beats ORM Complexity
Embracing SQL fosters collaboration. Many developers, even those who do not specialize in databases, can read and understand SQL. Debugging a query is much easier when you see the actual statement. When the actual SQL is transparent, debugging is streamlined. You can directly execute queries, examine execution plans, optimize indexing strategies, and quickly identify performance bottlenecks.
By keeping SQL visible and under your control, you avoid the black-box effect that heavy ORMs introduce. You gain confidence in how your system manages data, and you free yourself from the hidden complexities that lurk in generated queries.
When Layers Become Obstacles
Clean Architecture, Hexagonal Architecture, and Onion Architecture all promise clear separation of concerns. They aim to organize code into layers so that business logic stays independent from infrastructure details. That sounds good in theory, but I have seen these architectures create:
- Extra Layers of Indirection: Every new layer requires its own interfaces, modules, or adapters. Simple features end up scattered across multiple files.
- Slower Onboarding: New developers must learn the architecture’s rules before they can write a line of real code. This adds friction and can lead to confusion.
- Reduced Velocity: Strict layering means each change can trigger edits in multiple layers or modules. Even small adjustments involve shuffling data across boundaries.
The motivation behind these patterns is understandable. But in practice, the overhead can outweigh the benefits. Many teams apply these formal structures to every project big or small only to discover that they slow down delivery. They end up with complex abstractions that do not always map to real business needs. All those extra layers do not guarantee better code. In many real-world projects, I have seen them lead to more complexity, not less.
The Trap of Over-Abstraction: Rethinking DRY
“Don’t Repeat Yourself” is a longstanding principle that aims to reduce code duplication. I used to chase duplication everywhere. If I saw the same line of code in two places, I wanted to merge it. That seemed smart at first, but it introduced new problems:
- Tight Coupling: A shared utility or class that lumps together logic from different contexts ties those parts of the codebase together. A small update in one part might break another.
- Reduced Clarity: Sometimes repeating a few lines in separate modules is clearer. A generalized function might require mental gymnastics to figure out what it does in each scenario.
- False Economy: DRY for the sake of DRY wastes time. A tiny update for one case might break another, forcing more fixes down the line.
I learned to balance DRY with common sense. Duplication can be bad, but forced abstraction can be worse. If extracting common code makes a module harder to understand or maintain, it is not worth it. Repetition is not a crime if it keeps the system simpler and helps each part evolve on its own.
Conclusion: Design for Clarity, Not Trends
After three decades in software development, one truth stands clear: effective software solutions prioritize simplicity, clarity, and alignment with genuine business needs.
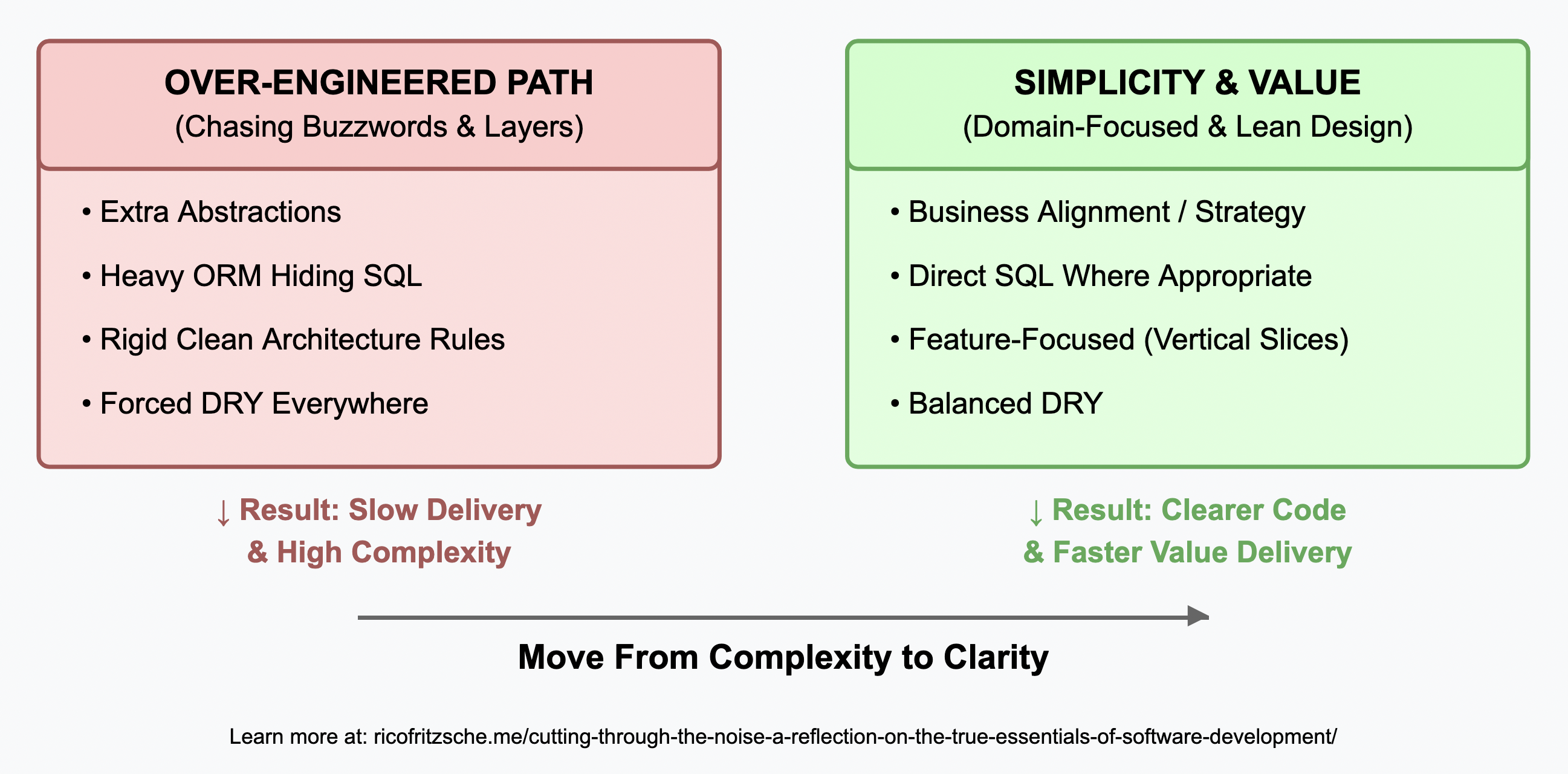
Trends and frameworks come and go, but fundamental principles remain unchanged:
- Favor explicitness over unnecessary abstraction. Clarity in code and architecture reduces complexity and maintenance costs.
- Align architecture with actual business needs. Strategic context trumps theoretical purity.
- Optimize for maintainability and readability first. Elegant code is valuable only if it can be clearly understood and efficiently maintained.
- Embrace SQL for its transparency and power. Visibility into your data operations enhances debugging, performance, and team collaboration.
- Use abstraction judiciously. Simpler solutions that occasionally accept duplication can be superior to rigidly forced abstractions.
Ultimately, staying grounded in practical realities, rather than chasing the latest buzzword or trendy methodology, ensures that software remains maintainable, adaptable, and truly valuable.
Cheers!