Context, Rules, Decisions: The Formula for Better Domain Models
Moving Beyond Mutable Objects to Explicit Business Logic

Have you ever wondered why object-oriented design sometimes feels overly complex, despite its promise of clarity and encapsulation? What if the fundamental problem isn't how we encapsulate data, but rather how we combine and manipulate it? Could it be that our software becomes complicated not because of the domain itself, but because of the way we've learned to structure it?
For many years, object-oriented practices defined my software development approach. Instantiating objects, manipulating them through their methods, and then persisting their state. But this cycle of instantiate–mutate–persist felt rigid, tangled, and unnecessarily complicated.
Then I started evaluating simpler, more natural paths, shifting toward pure domain logic through Rules and Decisions. Instead of mutating complex object graphs, imagine providing immutable data as input, evaluating clear and deterministic rules, and receiving new immutable data as output. No hidden state changes, no side effects, just straightforward, predictable transformations.
What if the true heart of your domain logic isn't the objects you instantiate, but rather the pure rules you apply? How might this change your perspective on complexity, maintainability, and clarity?
In my previous article on Aggregateless Event Sourcing, I described how removing aggregates simplifies event-driven architecture. Now, let’s build on that idea by exploring rules and decisions explicitly, and how moving away from mutable objects toward pure, explicit logic can simplify your domain modeling. Let's dive into a more intuitive, functional, and practical way of thinking about software, one free from unnecessary complexity and rich with clear, actionable insights.
Rules: Capturing Your Domain Clearly
When we build software, we’re translating real-world business rules into logic. These rules don't originate in code. They come directly from the domain experts, stakeholders, or users who deeply understand the problem you’re solving.
A Rule, then, is first and foremost something your business defines clearly:
- "A tracking device can only bind to one asset at a time."
- "A sensitive asset can only accept certified tracking devices."
- "Devices cannot be reassigned until unbound from their current asset."
Notice something essential here: these rules are not technical. They express how the business itself naturally operates and what it expects from the system. They provide precise, explicit constraints and guidelines reflecting the real-world domain.
Your job as a software developer isn't to create these rules; your job is to clearly capture and faithfully reflect them in code.
Rules Are Defined by the Business, Not by Technology
When business experts say, "We can’t ship fragile goods without special packaging" - that's a domain rule. It's simple, explicit, and free from implementation details.
As software developers, our first responsibility is to make sure these business rules remain just as clear and explicit when we translate them into code. We don't want these rules scattered across multiple layers, objects, or services. Instead, we keep them simple, clearly expressed, and directly aligned with how the business thinks.
From Domain Rules to Decisions
In software, a decision is how we explicitly apply these business rules to a specific scenario:
- "Given the current state and the requested action, what should happen?"
- "Should this shipment be allowed to proceed?"
- "Is this device allowed to bind to that asset?"
Decisions take the clearly defined rules from your domain and explicitly apply them, resulting in an outcome, usually expressed as an event describing precisely what happened or why it couldn’t happen.
Keeping Rules Pure and Clear
Once we've captured business rules clearly from the domain, our software benefits tremendously by representing these rules explicitly and purely:
- No side effects.
- No hidden state mutations.
- No surprises.
The clarity and purity of your rules reflect the clarity and explicitness of the business domain. It ensures the software remains understandable, maintainable, and directly aligned with real-world expectations.
From Business Rules to Clear Code
We've clarified that rules come directly from the business domain. They're the guidelines and constraints stakeholders define clearly. But how do we make these explicit domain rules visible and intuitive in code?
When writing clear, maintainable code, it's essential to explicitly represent your business rules. To illustrate, let’s continue with our logistics scenario, specifically the feature of binding a device to an asset.
The domain logic is expressed through a pure function named decide. Its signature clearly reflects the necessary input: the historical events of the device and the asset, and the command itself:
pub fn decide(
device_events: &[Event],
asset_events: &[Event],
cmd: BindDeviceCommand,
) -> Result<Vec<Event>, BindError>
Within this function, your business rules are clearly and explicitly represented by iterating over past events. For example, to determine if the device even exists, the function checks the historical events:
let device_exists = device_events.iter().any(|e| matches!(e, Event::DeviceRegistered { .. }));
if !device_exists {
return Err(BindError::DeviceNotFound);
}
Similarly, before binding a device, we must know if it's already bound or retired. This, too, involves inspecting past events:
let device_retired = device_events.iter().any(|e| matches!(e, Event::DeviceRetired { .. }));
if device_retired {
return Err(BindError::DeviceRetired);
}
let current_binding = device_events.iter().rev().find_map(|e| match e {
Event::DeviceBoundToAsset { asset_id, .. } => Some(asset_id.clone()),
Event::DeviceUnboundFromAsset { .. } => None,
_ => None,
});
if let Some(bound_asset) = current_binding {
if bound_asset == cmd.asset_id {
return Err(BindError::DeviceAlreadyBound);
}
}
These checks are straightforward, transparent, and directly aligned with the rules your business domain defines. Notice how this logic makes it explicit exactly under which conditions the binding will proceed or fail.
And if a rule isn't fulfilled, we explicitly indicate the reason through a clear, domain-specific error:
#[derive(Debug)]
pub enum BindError {
DeviceNotFound,
AssetNotFound,
DeviceAlreadyBound,
DeviceRetired,
}
The explicit domain errors in the code directly reflect and reinforce the Ubiquitous Language of your domain.
By clearly naming errors such as DeviceNotFound, AssetNotFound and DeviceAlreadyBound, the code precisely reflects the way in which domain experts would discuss these situations. These explicit error messages closely mirror the language that domain experts naturally use in conversation, rather than using generic or technical terms.
This close alignment of your code with the language of the domain creates clarity and transparency. It ensures that everyone involved, including developers, stakeholders and domain experts, understands precisely what is happening, why decisions were made and which business rules apply. It also overcomes the communication issues that are often encountered in software projects, providing direct support for the principle of Domain-Driven Design (DDD) of building software around a shared, consistent Ubiquitous Language.
How a Command Defines the Context
In typical object-oriented approaches, the context in your domain is typically predefined through aggregates (clusters of entities and value objects) bound together with rigid boundaries. But I've found this approach too limiting and rigid for real-world applications, especially in domains that are naturally dynamic.
When embracing explicit domain rules and pure decisions, the context emerges naturally from your commands. Each command represents a specific intention or use case clearly defined by your domain experts, and therefore each command creates its unique context.
Let’s consider again the simple command of binding a device to an asset. When your system receives this command, the context it needs to evaluate is explicitly shaped by that command: it must load exactly those events related to the specified device and the specified asset. There’s no need to load unrelated or unnecessary information, only the data explicitly relevant to the decision at hand.
The context, therefore, is simply defined by these explicit boundaries of intent: "I want to bind this specific device to this specific asset right now."
Your decision-making logic then explicitly retrieves exactly the historical events that matter for evaluating your rules: events about the current status of this device, events indicating if the asset is ready or already in use. Your rules evaluate these relevant events directly, producing an explicit decision.
This feature-related context is inherently simpler and more intuitive. It avoids the artificial complexity of rigid aggregates or complicated object graphs. Instead, the context is exactly as broad or narrow as required by the actual use case.
The context would naturally change if the command were different (e.g. if it were to be "unbinding a device"). In this case, you would look for events relating to current bindings and previous assignments. The context would dynamically shift to match the command, making it clear and intuitive.
This is precisely why explicit commands and pure rules simplify your software. You directly represent the domain's real-world intentions, clearly define exactly what's relevant, and avoid unnecessary complexity. The code reflects how your domain experts think about their business.
Reconstructing State from Events
With a clear understanding that each command defines its context, the next logical question arises: how exactly do we retrieve and rebuild the current state needed to make our decisions?
The answer is straightforward. Your application's current state isn't stored in fixed objects or database tables that directly represent entities. Instead, your state is dynamically reconstructed from pure events. Events are immutable records of past actions or occurrences.
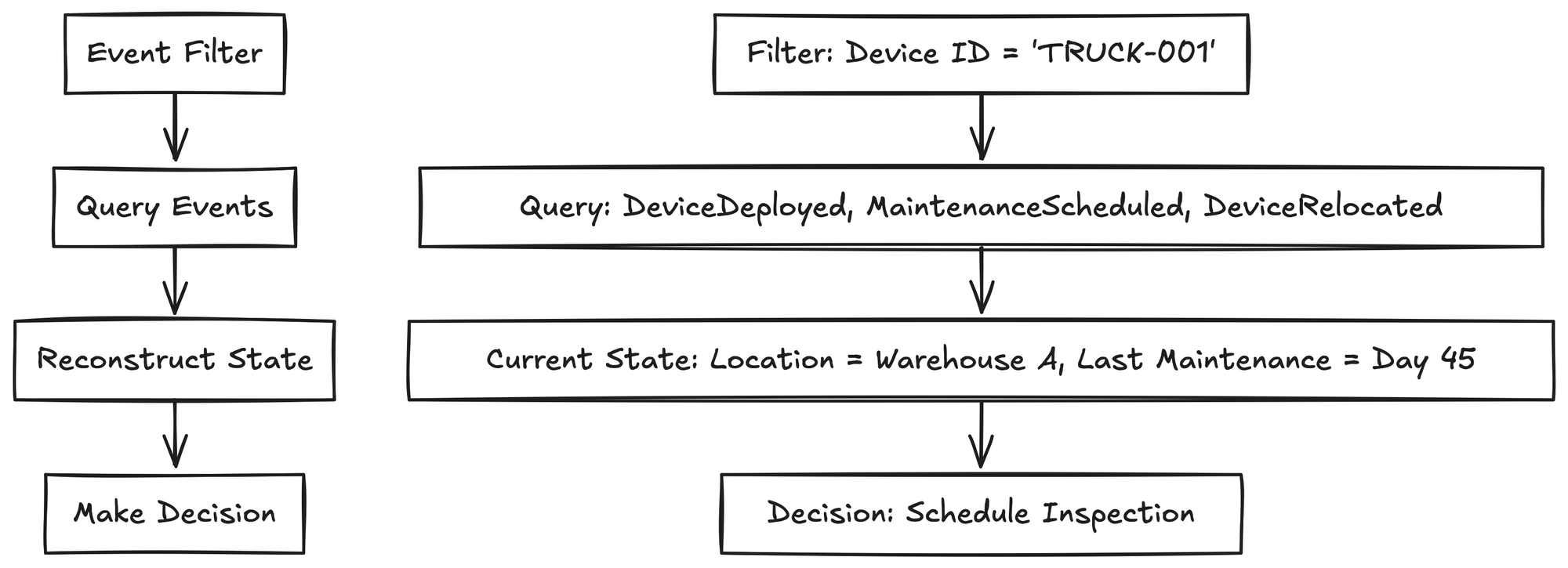
Whenever your application receives a command, it queries exactly those events relevant to its decision. To do this efficiently and explicitly, we define clear filters for the event store. Each filter explicitly describes:
- Which types of events we’re interested in.
- Any specific attributes those events must contain (for example, "device ID = 123").
Here's how a simple event filter might look in code, clearly expressing this idea:
#[derive(Debug, Clone)]
pub struct EventFilter<'a> {
pub event_types: &'a [&'a str],
pub payload_preds: HashMap<&'a str, Value>,
}
impl<'a> EventFilter<'a> {
pub fn new(event_types: &'a [&'a str]) -> Self {
assert!(!event_types.is_empty(), "EventFilter needs ≥1 event type");
EventFilter {
event_types,
payload_preds: HashMap::new(),
}
}
pub fn with_pred<V: Into<Value>>(mut self, key: &'a str, v: V) -> Self {
self.payload_preds.insert(key, v.into());
self
}
}
Why is this important?
Instead of retrieving everything or relying on arbitrary, fixed aggregates, your filters are explicit about what events matter. For example, to determine whether a device can be bound, you explicitly query events such as DeviceRegistered, DeviceBoundToAsset and DeviceRetired. You also explicitly filter for the specific device you're deciding about (e.g., "device_id = 123").
By replaying just these relevant events, your application rebuilds a precise, meaningful snapshot of the current state needed for the decision. This state is fresh, accurate, and directly aligned with your current context. There’s no stale or redundant data, and no rigid boundaries limiting your flexibility.
This approach makes state reconstruction clear, simple, and highly performant. Your decisions remain accurate, straightforward, and closely aligned with your business reality.
Separation of Concerns
It is important to understand that querying events from your event store is not one of the typical tasks of your pure decision logic. Queries involve side-effects (they access external resources like a databases or files) which means they should remain clearly separated in what we call the Imperative Shell.
The imperative shell handles loading events explicitly from the event store, based on the filters defined earlier. Then, it passes these relevant events as immutable data into your pure domain logic. Here's a small, practical example demonstrating this clearly:
pub async fn load(pool: &PgPool, filter: EventFilter<'_>) -> anyhow::Result<Vec<Event>> {
let mut query = "SELECT payload FROM events WHERE event_type = ANY($1)".to_string();
let mut params: Vec<&(dyn sqlx::types::Type<Postgres> + Sync)> = vec![&filter.event_types];
for (i, (key, value)) in filter.payload_preds.iter().enumerate() {
query.push_str(&format!(" AND payload @> ${}", i + 2));
params.push(value);
}
let rows = sqlx::query_with(&query, params)
.fetch_all(pool)
.await?;
let events = rows
.iter()
.map(|row| serde_json::from_value(row.get("payload")))
.collect::<Result<Vec<Event>, _>>()?;
Ok(events)
}
The imperative shell takes care of loading exactly what's needed from your event store. Then it passes the loaded, immutable events into your pure decision logic, which has no direct access to databases or external systems. The pure logic remains side-effect-free, predictable, and straightforward to test.

Benefits of Clear, Pure Domain Logic
At this point, you might wonder: is all this effort around explicit rules, pure decisions, and feature-related contexts really worth it? After all, it's quite a shift from the object-oriented ways of thinking. But here's the good news: adopting this simpler, more explicit approach to domain logic has clear and tangible benefits.
First, there's testability. Because rules and decisions are pure and side-effect free, testing becomes straightforward and fast. There’s no complicated mocking, no database connections, and no cumbersome setups. Testing a decision simply involves passing immutable data in and confirming the expected result comes out. Clear rules mean your tests directly reflect business scenarios, making them valuable and relevant.
Next, think about maintainability. If domain logic explicitly reflects the actual business rules provided by domain experts, the code naturally stays in sync with business needs. If a rule changes (say, the conditions under which devices can bind to assets) the exact place in your code to adjust is immediately clear. Changes in business logic no longer cascade unpredictably through complicated object graphs; instead, they're clearly defined and simple to manage.
Finally, consider debugging and reasoning about your software. When unexpected behavior arises, finding its source is intuitive and fast. You can replay exactly the same events, observe explicitly how your rules evaluate these events, and clearly understand the resulting decisions. There's no hidden state, no buried logic, just clear, visible steps you can easily follow.
Overall, clear and pure domain logic doesn't merely simplify code. It enhances your ability to reason about your system. It improves collaboration, aligns developers and domain experts, and ultimately creates software that’s robust, flexible, and deeply aligned with real-world needs.
Cheers!