Aggregateless Event Sourcing
Why Removing Aggregates Unlocks Simplicity, Flexibility, and Independent Feature Slices

When building systems using Domain-Driven Design (DDD) and Command Query Responsibility Segregation (CQRS), aggregates are usually at the core. An aggregate groups related entities and value objects into a single unit. This unit ensures consistency and enforces business rules through transactional boundaries.
In theory, this makes perfect sense. But reality shows a different story. Aggregates introduce complexity. They quickly become outdated and force constant refactoring. The reason is that business processes naturally change, but aggregates tie data and logic together too tightly. When something changes in your business, the aggregate needs adjustment, even if the change seems small .
For example, consider an Asset Tracking system managing devices and assets. Initially, two aggregates might seem logical: one aggregate for Assets and another for Devices. Each aggregate independently manages its lifecycle and business rules. The Asset aggregate ensures rules like "only one device per asset at a time." The Device aggregate ensures rules like "a device cannot be bound to multiple assets simultaneously."
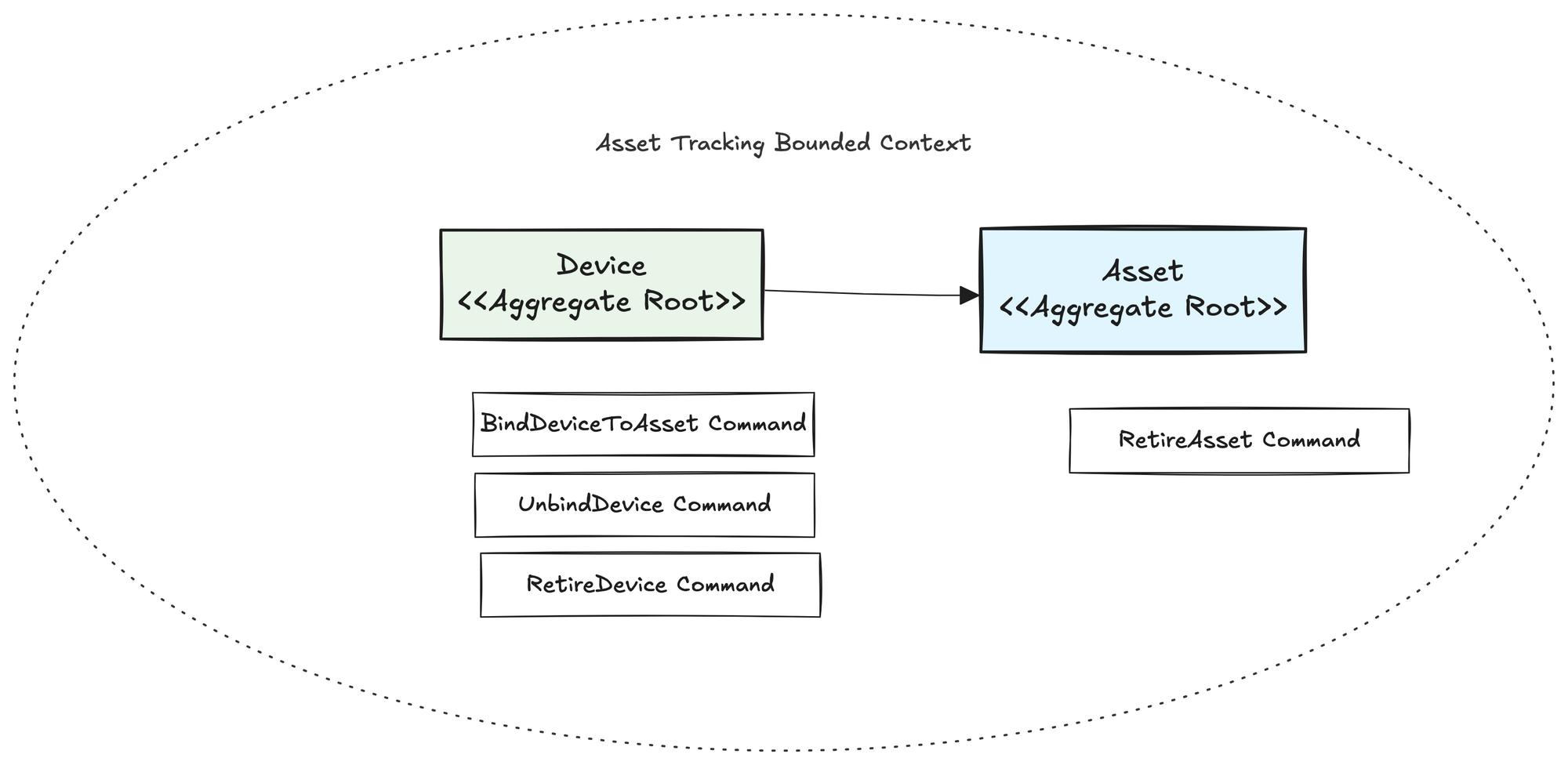
But here’s the problem: Binding a device to an asset crosses aggregate boundaries. To handle this properly, developers introduce domain services or additional events, creating unwanted complexity and indirect coordination.
Even worse, aggregates often blend technical management (device lifecycle) with pure business logic (asset tracking). Mixing these concerns makes it difficult to evolve each independently. Real business scenarios rarely match static consistency boundaries set by aggregates.
Your initial aggregate boundaries quickly prove either too coarse or too fine, forcing constant and costly refactoring. Aggregates become complicated to maintain and difficult to evolve naturally. Developers and business experts both feel frustrated, struggling to clearly express the actual behavior of the business.
Instead of focusing on business logic, everyone spends energy on handling overly rigid structures.
The real issue is not aggregates themselves, but consistency. Aggregates were invented as a solution to maintain consistency. But they force us into rigid structures that rarely match evolving real-world needs.
So, the right question isn’t how to define better aggregates.
The right question is: What exactly do we want to keep consistent?
Rethinking Consistency: It's All About Context
If aggregates themselves aren't the real problem, what is?
The true problem is consistency. Aggregates exist because consistency matters. But consistency doesn’t depend on aggregates or entities. It depends on context.
What exactly is context?
In object-oriented approaches, context is an object network. In relational databases, it's a set of data records. But what if context was simpler? Instead of complex object graphs or rigid data structures, what if context was defined only by the facts we need for a specific decision?
Imagine you want to bind a device to an asset. What information do you really need? You need to know:
- Does the asset exist and isn't retired?
- Does the device exist and isn't retired?
- Is the device currently free (not bound to another asset)?
This defines your context. You don't need anything else. You don't care if the asset was renamed or if the device was previously retired and then activated again. These details are irrelevant for this specific decision.
In practice, context is simply the set of facts (events) relevant to your decision. You define context by querying events. If the context remains unchanged since you checked it, you apply your changes. If not, you reconsider. It's as straightforward as that.
But there's one important point: Since the context check takes some time, especially in distributed systems, the underlying context might have changed between checking and applying changes. To handle this, the check and the change must happen together. This combined step must be atomic. Atomic means the query and insert happen as a single, indivisible step.
With that, we completely remove rigid entities and aggregates from our mental model. There's no object, no object graph, there are only data structures (events, commands) and pure functions (decisions).
Pure Events: Facts without Boundaries
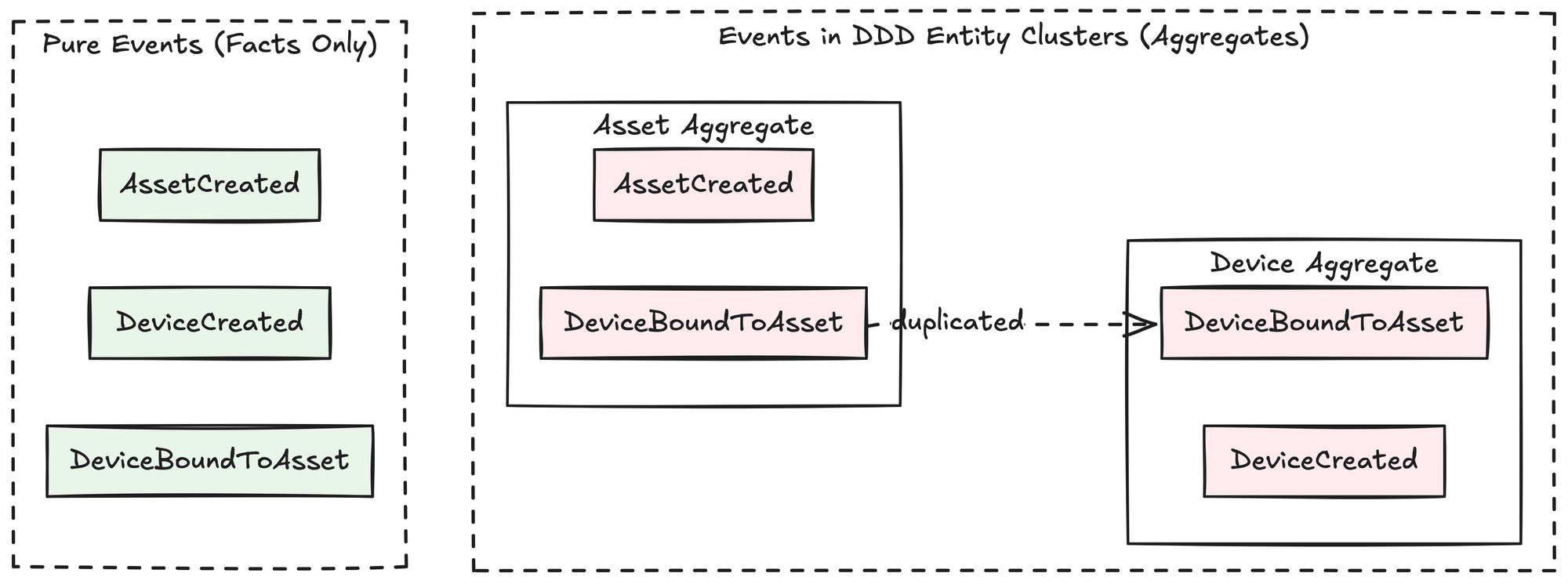
In traditional aggregate-based systems, events are closely tied to aggregates. The event reflects the state or changes within the aggregate. This coupling makes events less flexible. An event like DeviceBoundToAsset could be duplicated across multiple aggregates, each with its own interpretation and state management. This duplication creates complexity and rigidity.
But what if events could stand on their own? What if events were simply facts, pure and independent from any aggregate or rigid entity?
This is exactly what we aim for with aggregateless event sourcing. We remove the notion of an event belonging to an aggregate entirely. Instead, an event simply records a fact that occurred: no assumptions, no boundaries, just facts.
Here’s what a pure event looks like in practice:
{
"DeviceRegistered": {
"deviceId": "550e8400-e29b-41d4-a716-446655440000",
"registeredAt": "2025-06-22T10:00:00Z"
}
}
This event fully describes itself. It references an entity (the device) via its identity (ID), but it doesn't depend on aggregates, external context, or additional tags to convey its meaning. It clearly conveys the fact: a device with a certain ID was registered at a certain time.
Similarly, here's another example without an explicit identifier:
{
"SystemUpdated": {
"version": "v2.0.5",
"updatedAt": "2025-06-22T11:30:00Z"
}
}
This is another pure event. It has no associated entity, yet it fully describes what happened.
Pure events simplify your system dramatically:
- Events can be easily reused and interpreted by different feature slices independently.
- There's no duplication across aggregates.
- New behaviors or decisions can emerge at any time from existing events without needing structural refactoring.
When events become pure facts, recorded chronologically, your consistency boundaries become flexible and simple. They depend entirely on what your current decision or action requires.
A common question: if an event doesn't reference an aggregate or entity explicitly, how do we identify what it relates to?
The answer is simple: you don't need tags or IDs in every scenario. The event itself already includes all information required. When needed, the context is always defined through querying the facts stored in your event log.
Tagging IDs explicitly isn't necessary because the event itself is already self-descriptive. Even scenarios without explicit identifiers still fully convey their meaning through pure data. This naturally reduces complexity, as there's no need for additional indexing or indirect referencing.
Entities Revisited: Context, not Rigid Representations
You might wonder, if we still have IDs in events, aren’t we still dealing with entities?
Conceptually, yes! But importantly, these entities are not rigid objects with fixed representations. This is exactly the pitfall of object-oriented thinking: it tries to define entities as static, uniform structures: “A device is always a device, with the same attributes everywhere.”
In practice, entities like a device aren't rigid. They're flexible, context-dependent manifestations based on the needs of each individual decision or command. Sometimes a device is just an ID, name pair, other times it’s ID, longitude, latitude, or even entirely different attributes.

Every feature slice, every command, and every projection shapes its own representation of an entity. There is no single, canonical, or rigid definition enforced everywhere.
This dynamic view clearly aligns with the idea of pure events and contexts defined by queries. It frees your system from rigid object-oriented representations, allowing natural adaptation to evolving real-world scenarios.
Handling Concurrency Simply and Clearly
Without aggregates, how do we handle concurrency and consistency? The traditional aggregate approach enforces concurrency through strict transactional boundaries. If we remove aggregates, we lose those boundaries. Does this create a problem?
Actually, no. It simplifies things significantly.
Instead of aggregates, consistency is managed through event queries. When a decision must be made, your context is clearly defined by the set of relevant facts you query. This query spans the context based on events. After querying, you make a decision. But there's one key requirement: You must ensure the context remains unchanged from the moment you read it until you record the new event.
Here’s a practical example. Imagine you want to bind a device to an asset. You query events like these to build your context:
SELECT *
FROM events
WHERE event_type IN ('DeviceRegistered', 'AssetRegistered', 'DeviceBoundToAsset', 'DeviceUnboundFromAsset')
AND (
payload->>'deviceId' = '550e8400-e29b-41d4-a716-446655440000'
OR payload->>'assetId' = '660e8400-e29b-41d4-a716-446655440000'
)
ORDER BY sequence_number;
Based on this query, your system sees whether the device and asset exist and if the device is free for binding.
After making your decision (e.g., deciding it's safe to bind), you apply your new event or events, but you apply it atomically. That means your insert operation checks again, ensuring no new events have appeared that would change your context.
This ensures consistency clearly and simply. It removes complex locking mechanisms or pessimistic concurrency approaches. Instead, consistency is entirely about facts and queries.
Here’s the practical step clearly stated again:
- Query events defining your context.
- Make your decision based on these events.
- Atomically insert your new event, verifying the context hasn't changed.
If the context changed meanwhile, you simply retry your decision. There's no complicated locking or shared aggregate state.
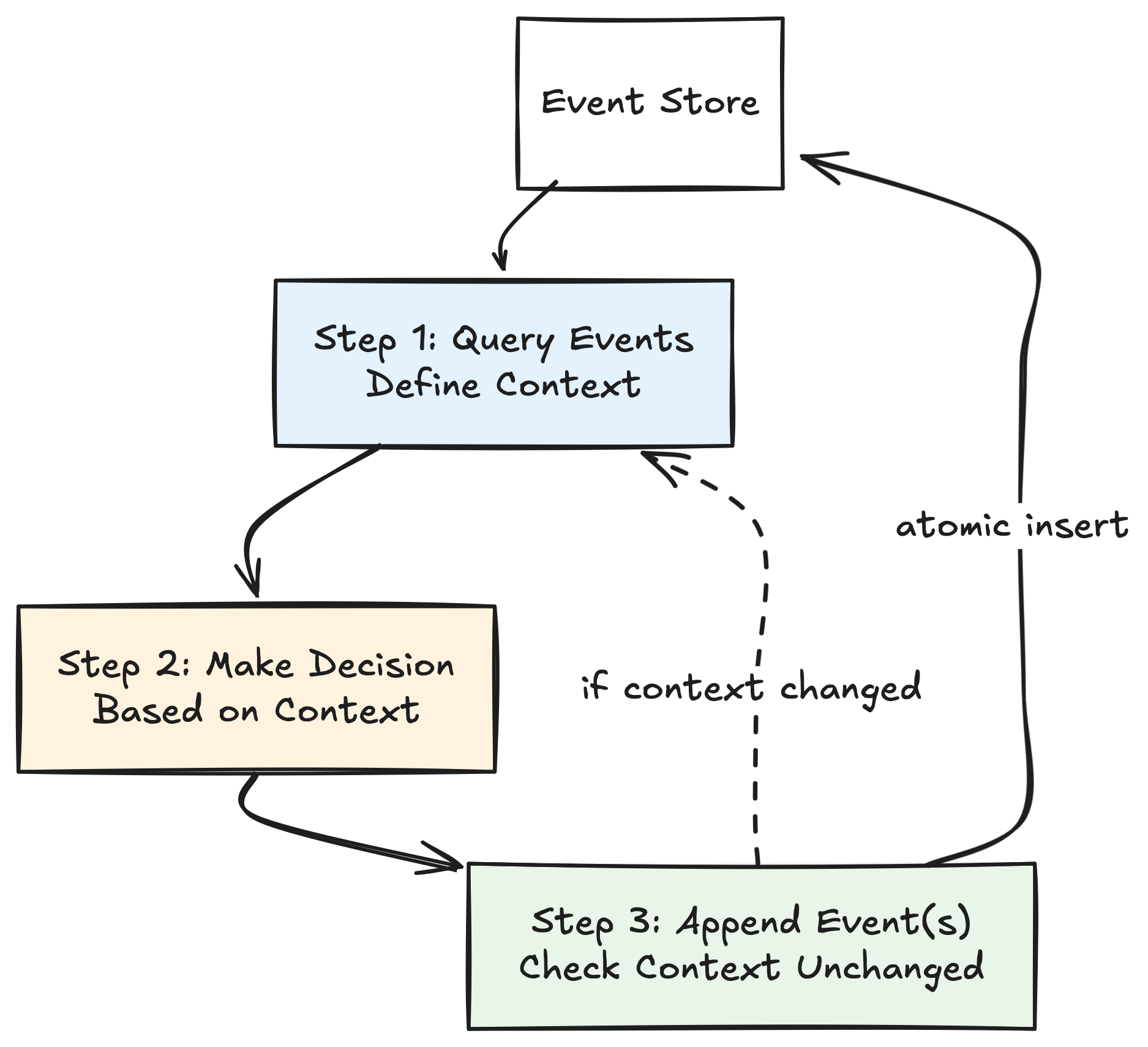
Consistency isn't about aggregates; it's about ensuring the context remains unchanged during decision-making. Since this context definition comes purely from queries against recorded facts, consistency becomes a straightforward atomic check. This is a natural fit for distributed systems.
This simple and clear approach reduces overhead. It lets your feature slices remain truly independent. Each feature clearly defines and manages its consistency without complex orchestration or hidden dependencies. New feature slices or new decisions within slices are easy to add. They don't affect or break existing behavior.
Pure Logic, Pure Persistence: Truly Independent Feature Slices
One major benefit of removing aggregates is the natural separation of logic and persistence. Events become pure persistence. Decisions become pure logic. They live separately but complement each other clearly.

This perfectly fits the principles of functional programming, which separates pure logic from side effects (like persistence).
Events represent side effects: things that happened.
Logic represents decisions: what should happen based on current facts.
In practical terms, events are stored in a simple, chronological event store. There’s no assumption about how events will be used. You don't predefine rigid structures or schemas. You simply store events as they happen:
CREATE TABLE events (
sequence_number BIGSERIAL PRIMARY KEY, -- total ordering
occurred_at TIMESTAMPTZ NOT NULL DEFAULT now(),
event_type TEXT NOT NULL,
payload JSONB NOT NULL,
metadata JSONB NOT NULL DEFAULT '{}'
);
CREATE INDEX ix_events_type ON events(event_type);
CREATE INDEX ix_events_payload_gin ON events USING GIN (payload);
On the logic side, feature slices define their contexts explicitly through queries. Each slice clearly determines what facts it needs to know to make decisions.
Each feature slice is completely self-contained. It can evolve separately without affecting other slices. New slices or new logic within existing slices can appear anytime, easily consuming existing events. The system structure remains clear and straightforward. Logic remains pure, making testing easy and predictable.
Persistence (event store) becomes an imperative shell that simply records facts. Logic remains pure, functional, and entirely free from side-effects.
The event store, therefore, becomes the shared reality for all feature slices, capturing everything that has happened in the system, clearly reflecting the sum of all business activity.
This pure separation finally lets us overcome the rigidity imposed by traditional aggregates and entities. Feature slices become truly independent, naturally adapting to real-world business changes.
Embracing Simplicity: Just Clear Concepts and Practical Simplicity
The concept is simple:
- We remove aggregates, rigid entities, and domain services completely.
- We define consistency purely through querying relevant facts.
- We clearly separate pure logic (decisions) from pure persistence (events).
Each feature slice remains clear and simple, making your entire system easy to understand and maintain.
This simplicity naturally aligns with core architectural principles:
- Feature Slices: Incremental evolution is clearly manifested in the code structure itself.
- Event Sourcing: Pure facts are the simplest and smallest common denominator between slices.
- Command Query Separation (CQS): Separating state changes (commands) from state queries (projections) clearly identifies and isolates constraints.
- Functional Core, Imperative Shell (FCIS): Clearly separating consistency checks and domain logic from state changes and projections. Pure functions are then naturally applied to pure facts, projected specifically within each command context for clarity and simplicity.
In my opinion, the real benefit is a system that stays flexible, understandable, and naturally aligned with evolving business needs. By fully overcoming object-oriented thinking, we build a simpler, clearer, and genuinely agile architecture.
Introducing aggregates was a good intention, I guess, but they aren't necessary either. By clearly defining consistency through pure facts and queries, we achieve simplicity and flexibility far beyond what traditional approaches allow.
It's time to shift from rigid object-oriented models to clear, flexible, and simple aggregateless event sourcing.
Special thanks to Ralf Westphal for the insightful discussions, thoughtful critiques, and valuable ideas that helped clarify and refine this article. Read also Ralf's perspective on this topic here.
Cheers!