Simply Event Sourcing
Aggregates Were Never Required — Command Context Consistency and DCB’s Tag-Based Contract

Why do I write this article? Because I see a lot of confusion around Event Sourcing. In my practical work over the last few years, I have repeatedly seen teams perceive Event Sourcing as something complex that is not always necessary. I think the reason for this is easy to explain and understand. The enterprise software development I encountered over the last decades was shaped by object-oriented programming and the tactical design patterns of Domain-Driven Design. For more than a decade, this was also how I thought Event Sourcing worked. In my mind, Event Sourcing was linked to aggregates.
This article was originally published here:

The problem with this entire approach is that we always have to start by designing aggregates and building centralized models of objects like Customer or Order in order to establish consistency boundaries. This means making too many assumptions early on about how things might be. All subsequent behavior must inevitably fit into this structure. Experience has shown me that this makes the development process inflexible and cumbersome.
I really came to understand this when I was working on the idea of self-contained feature slices but was still stuck thinking within the confines of Domain-Driven Design (DDD). It is impossible to construct a slice independently as long as it depends on central object structures that own the state, define the consistency boundaries, and determine how events are stored.
Almost exactly a year ago, in June 2025, I published an article titled Aggregateless Event Sourcing¹, which explored this idea. In the article, I explained that aggregates are not necessary to achieve consistency. The context arises from the command, which is why Ralf Westphal² and I now use the term Command Context Consistency for this approach. Event Sourcing itself is simple and does not depend on the tactical design patterns of DDD.
Two years before my article, in April 2023, Sara Pellegrini³ published the first chapter of her Kill the Aggregate series. She described the limitations imposed by aggregates and later showed that a command handler can build the exact data structure needed for a particular decision from the relevant event history. There is no need to rebuild a permanent object structure containing everything that happens to share the same noun.
Looking back, I realize that the title of my own article shows how strongly Event Sourcing was still linked to aggregates in my mind.
Calling something aggregateless gives the aggregate a position in the original definition and then describes how to remove it.
The definition I use is close to the one Mathias Verraes⁴ formulated in 2019:
A system is eventsourced when the single source of truth is a persisted history of the system’s events; and that history is taken into account for enforcing constraints on new events.
Martin Fowler’s⁵ description is similarly broad.
Event Sourcing ensures that all changes to application state are stored as a sequence of events.
It says that changes to application state are captured and stored as a sequence of events from which state can be reconstructed. Neither definition introduces aggregates, aggregate roots, entity lifecycles, or per-aggregate event streams.
Implementation Became the Definition
A common aggregate-based Event Sourcing implementation follows a familiar sequence. A command identifies an aggregate instance, the event stream belonging to that instance is loaded, an object is rebuilt from those events, a method is called on the object, and the resulting events are appended if the expected stream version still matches.
This is a coherent way to implement Event Sourcing. The aggregate acts as the decision structure and the concurrency boundary at the same time. The problem begins when this specific implementation is presented as the definition of Event Sourcing.
The aggregate pattern groups related entities and value objects into a unit for data changes and uses that boundary to protect consistency. When it is combined with Event Sourcing, the aggregate boundary is usually materialized as an event stream. Every event is assigned to one aggregate instance, and optimistic concurrency protects the version of that entire stream. The consequence is that once the aggregate boundary is embedded in the event stream structure, it becomes much harder to change later. It changes the order in which we think. Before recording a fact, we ask which aggregate owns it. Before implementing a command, we ask which aggregate must handle it. When a rule needs information associated with two aggregates, we immediately have a cross-aggregate consistency problem, although the business rule itself never mentioned aggregates.
The structure came first and the behavior was forced into it afterwards.
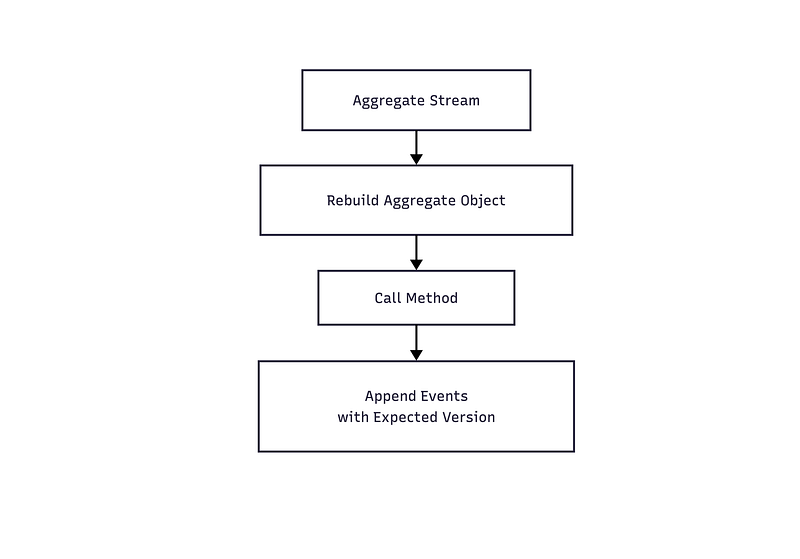
This also explains why aggregate-based systems tend to accumulate behavior around nouns. Commands that mention the same Customer, Order, or User are placed into the same aggregate even when they need completely different facts and protect unrelated rules. The aggregate provides one predefined boundary for all of them because they happen to share the same conceptual object.
But Event Sourcing itself does not require this boundary.
Start with the Decision
Consider a command that registers a user with a particular username. The decision requires an answer to a specific question: has that username already been claimed?
The relevant history might consist of events recording the registration, change, release, or reservation of that username. The command does not require every event ever recorded about every User object. It does not care whether another user changed a profile picture, accepted new terms, or updated a postal address.
The command context is the set of facts required to decide whether the username may be registered. From those facts, the Domain Capability⁶ handling the command derives temporary decision data representing whether the username is available. The capability applies the rule and, when the username is available, produces a UserRegistered event.
Another command involving the same user can require an entirely different context. Updating a display name and suspending an account both mention a user, but that shared noun does not prove that the same facts or the same concurrency boundary are required. Each command therefore requires its own view of the history.
This is the important inversion. The context follows the decision instead of the decision following a predefined object boundary.
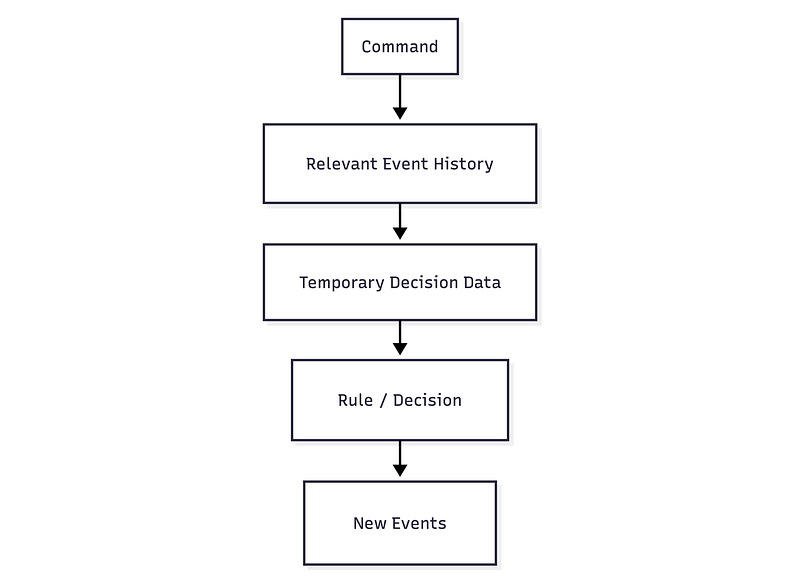
The event history remains shared because it represents what happened in the application. Its interpretation remains local because the Domain Capability handling a command selects and projects the facts required for that decision. The capability can therefore own its rules, its temporary decision structure, and the events it produces without depending on a central object that attempts to represent the entire application.
An event such as UsernameChanged is then a fact that can be interpreted wherever it is relevant. It does not have to be treated as an internal state transition owned by a User aggregate. A user identifier can still be part of the event data, but that identifier is data describing what happened rather than proof that the event belongs to a predefined aggregate stream.
Event History Is More Than an Audit Trail
The distinction between Event Sourcing and an audit log is important here.
A state-based system can update a row and then write an event describing the update. It can publish that event to a message broker and retain it indefinitely. This still does not make the event history the source of truth when the current-state database remains authoritative and future decisions are based on that database.
Under the definition used in this article, the direction is reversed. New state is expressed by recording new events. Derived state can be stored for efficient access, but it can be reconstructed from the event history. More importantly, the relevant history is considered when deciding whether the next events may be accepted. That second part separates Event Sourcing from merely projecting or analyzing an existing event log. This means that projections are derived data. They can be rebuilt, replaced, or designed for a specific query. They may be updated synchronously or asynchronously, depending on the requirements of the application. None of these choices changes which data is authoritative.
Consistency Is a Separate Question
Once a command has read its context and made a decision, another process may append a conflicting event before the command records its own result. The command would then be based on history that is no longer current.
Every practical implementation therefore needs a way to protect the relationship between the facts used for a decision and the new facts produced by that decision.
Aggregate-based Event Sourcing handles this with the expected version of an aggregate stream. The append succeeds only when no event has been added to that stream since it was read. This protects consistency, but it protects the entire stream. An unrelated event in the same aggregate stream also invalidates the decision and causes a conflict or retry.
Command Context Consistency (CCC)² takes the command’s actual context as the boundary. The Domain Capability handling the command selects the relevant events, derives the data required for the rules, and produces new events. During the append, the event store verifies that no relevant events have appeared since that context was read. Other events may have been recorded in the meantime, but they do not invalidate the decision when they do not match the context query. Consistency is checked against a context, and the stability of that context is ensured while recording the resulting events.
Dynamic Consistency Boundary (DCB)⁷ follows the same basic idea. A command queries the events required for its decision, and the append must fail when relevant events have been recorded since that context was read. At this level, DCB applies the same principle of Command Context Consistency. It protects the decision against concurrent changes in the relevant event history instead of protecting a predefined aggregate stream.
The difference is not what constitutes application state. In both CCC and DCB, the persisted event history represents the application state. The difference lies in how the relevant part of that history is made queryable for a command. In CCC, an event conceptually contains an event type, a sequence number, a timestamp, and a payload. CCC defines the conceptual requirements for protecting a command context, but it does not prescribe a concrete event store API or query representation. A context query may, for example, select events by type and apply a predicate such as accountId = "abc1234" to the payload. An implementation may add indexes, derived tags, or other access structures to execute such queries efficiently, but CCC does not require them. The producer therefore does not have to anticipate how other commands may later query the event.
DCB makes tags part of the required event store contract. A DCB event contains an event type, event data, and tags, while the event data remains opaque to the event store. Events are selected through the DCB query contract by event type and tags rather than by predicates against the payload. Any payload value needed to select events through this query contract must therefore be represented by a tag when the event is stored. For example, an account identifier contained in the event data may also be exposed as a tag such as account:abc1234. These tags therefore define a queryable view of the event at write time.
This is the actual distinction between CCC and DCB. Both retrieve the event context required by a command and protect the append with a query-based condition. In the usual read-decide-append flow, the condition detects whether relevant events have appeared since the command observed its context. CCC leaves the representation and execution of that query to the implementation. Tags, indexes, or other access structures may be introduced as optimizations. DCB makes event types and tags part of the required query contract while the event data remains opaque to the event store. Any value that a command must use for a selective consistency query therefore has to be exposed as a tag when the event is written. DCB is consequently a specific tag-based event store contract for applying the same consistency principle rather than a separate consistency model. Both CCC and DCB address consistency in an event-sourced system. Neither is a synonym for Event Sourcing.
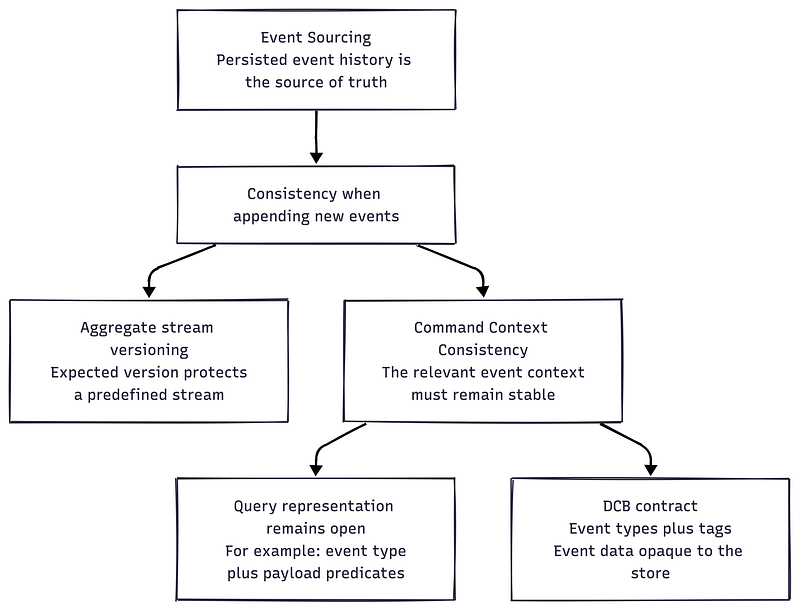
Aggregate stream versioning is another way to protect consistency within an event-sourced system. The meaningful comparison is therefore between aggregate stream versioning and consistency based on the command context: how each selects the relevant facts, detects conflicting changes, supports efficient queries, and allows the consistency boundary to evolve. CCC defines the principle without prescribing a particular query representation, while DCB specifies a tag-based event store contract for applying it. Comparing DCB directly with Event Sourcing therefore compares an event store contract for consistency with the persistence concept it supports.
CQRS and Event-Driven Messaging Are Separate Concepts
Command Query Responsibility Segregation (CQRS) is also regularly included in descriptions of Event Sourcing, although it addresses another question. CQRS separates the handling of commands from the handling of queries. Event Sourcing combines naturally with this separation because query-specific projections can be derived from the event history, but CQRS does not require Event Sourcing, and Event Sourcing is not defined by CQRS. Microsoft’s own architecture guidance⁸ describes Event Sourcing as a pattern that some CQRS implementations incorporate, rather than as the same pattern. The same is true for event-driven messaging. An event-sourced application may publish recorded events to other components, but the event store is not a message broker, and Event Sourcing does not require a distributed system. A single application using one relational database and an append-only event table can already be event-sourced when the event history is authoritative and participates in decisions.
Microservices, asynchronous projections, message brokers, distributed sagas, and aggregate frameworks are architectural choices that may appear in an event-sourced system. Combining all of them and presenting the result as Event Sourcing explains why teams perceive the concept as much more complex than it is.
A Simple Concept Still Requires Engineering
Calling Event Sourcing simple does not mean that every event-sourced system is easy to build. Production systems still have to deal with evolving event structures, atomic persistence, efficient access to history, derived views, external side effects, and failures. These are real engineering questions.
The point is that these questions should be discussed as individual design problems instead of being bundled into the definition of Event Sourcing. A system that serves millions of requests across several regions has different operational requirements from a single application using PostgreSQL. The persistence concept remains the same in both cases.
The same is true for consistency. A command that checks a unique username may require a narrow context. Another command may require facts about thousands of products or a globally ordered sequence. The boundary follows the rule that must be protected. Event Sourcing does not promise that every rule will be cheap or local, but it also does not require every rule to be forced through an object boundary chosen before the rule was understood.
This gives us a much simpler starting point. A command arrives with an intention. The Domain Capability handling it determines which recorded facts are relevant to that intention, derives the data needed for the decision, applies its rules, and produces new facts. Those facts are recorded only when the context on which the decision was based is still valid.
That is enough to describe the event-producing part of an event-sourced system. Everything beyond it is an implementation decision.
Conclusion
Looking back, Aggregateless Event Sourcing¹ was a necessary title for me at that point because it named what I was trying to remove from my own thinking. Today I see the limitation of the term more clearly. It still starts with the aggregate and then describes Event Sourcing as a variation that works without it.
But the truth is that Event Sourcing never required aggregates.
An event-sourced system persists its accepted facts as the authoritative history. The Domain Capability handling a command interprets the facts relevant to the decision, applies its rules, and produces new facts. Those facts are recorded only if the relevant context has remained stable. Aggregate stream versioning can protect a predefined stream. CCC defines consistency against the event context required by the command, while DCB specifies a tag-based event store contract for applying the same principle. Event Sourcing remains the underlying persistence concept.
Keeping these terms separate allows a useful discussion about each of them. Teams can evaluate whether an aggregate stream is an appropriate consistency boundary or whether the command’s actual event context should define it. They can then decide whether a DCB-compatible tag contract fits their access requirements or whether another implementation of CCC is preferable. None of these choices is a prerequisite for preserving facts as the source of truth.
That is why I dropped the qualification “aggregateless”: the approach I am describing is simply Event Sourcing.
Cheers!
Sources:
- Rico Fritzsche: Aggregateless Event Sourcing
- Ralf Westphal: Command Context Consistency
- Sara Pellegrini: Chapter 1 — I am here to kill the aggregate
- Mathias Verraes: Eventsourcing: State from Events Events as State?
- Martin Fowler: Event Sourcing
- Rico Fritzsche: Autonomous Domain Capabilities
- Dynamic Consistency Boundary: Specification
- Microsoft Learn: Command Query Responsibility Segregation (CQRS) pattern