OpenStreetMap Is Not a Routing Model And Treating It Like One Is Expensive
The structural misalignment between OSM’s flexibility and the deterministic demands of production routing systems.

When routing systems based on OpenStreetMap start to show cracks, the first reflex is usually to look at scaling, indexing, or infrastructure. Latency creeps up, tail behavior becomes unpredictable, cloud cost rises, and the instinctive reaction is to add capacity or tune queries.
But over the years I have found that the deeper issue usually sits somewhere else. It sits in an assumption that is rarely questioned: that importing OSM correctly means you now have a routing model.
That assumption is not a small technical shortcut. It defines the architecture that follows. And once the architecture is shaped around raw OSM semantics, correcting it later becomes disproportionately expensive.
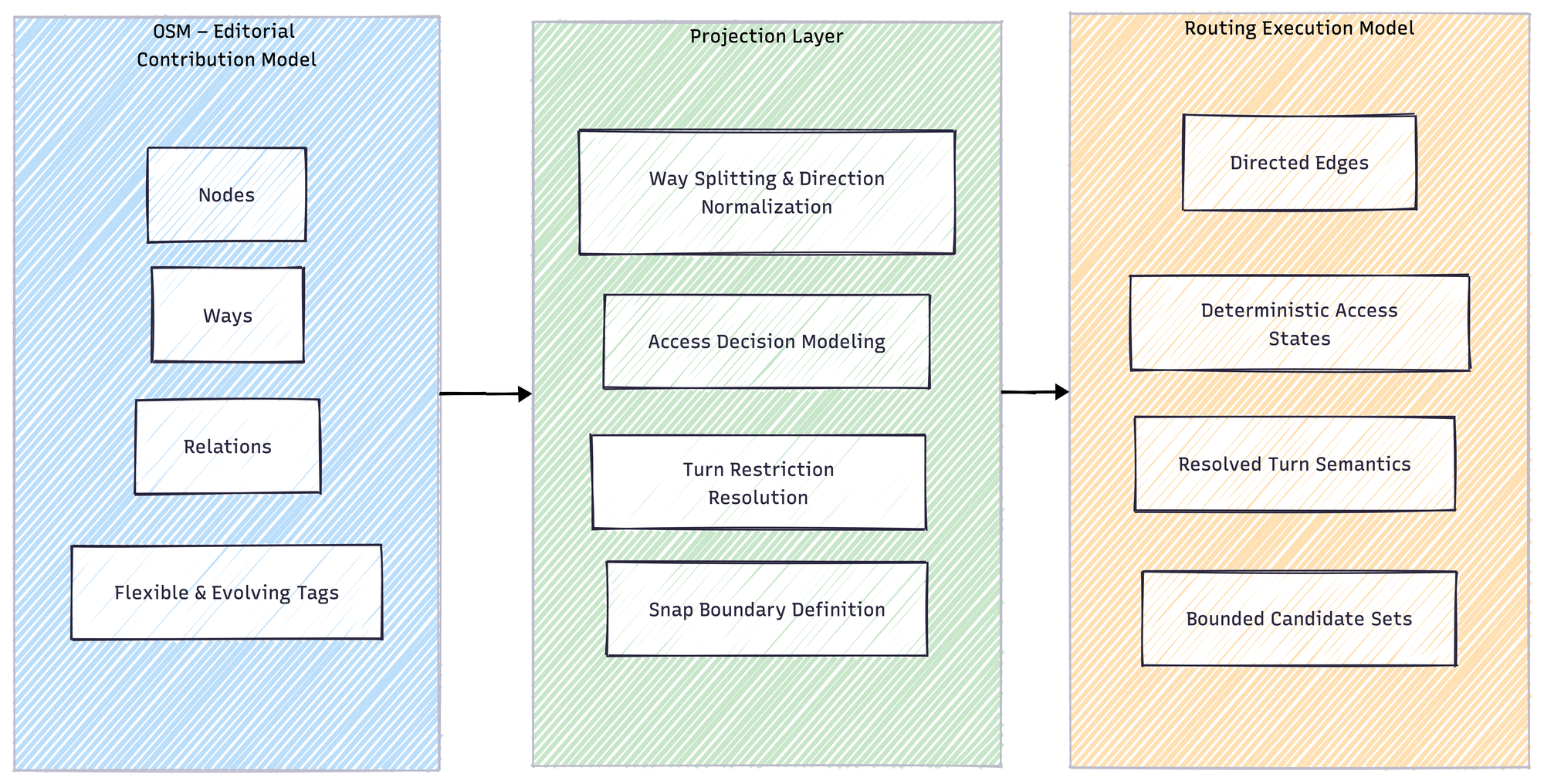
OpenStreetMap is an extraordinary system. It allows a distributed community to describe the world with remarkable flexibility. Nodes, ways, relations, and tags form a living, evolving representation of geography. That flexibility is its strength because it allows nuance, correction and growth.
Routing engines, however, operate under entirely different constraints. A routing core does not describe the world. It decides within it.
It needs deterministic edge semantics. It needs unambiguous directionality. It needs a stable execution graph that can answer the same question twice and produce the same result, even under concurrency and load. It needs decision logic that does not have to reinterpret metadata on every request.
OSM was never designed for that role. And when the two models are treated as interchangeable, subtle complexity leaks into the execution layer.
Access Legality Is Not a Property
Access legality often begins its life as tag evaluation. A tag says motor_vehicle = no, and so the edge is marked prohibited. That works until contextual reality enters the system.
None of the following are exotic: conditional access, vehicle classes, delivery exceptions, barrier overrides and time-dependent rules. They are standard.
If the routing engine evaluates these directly from raw OSM tags at request time, it is effectively reconstructing a decision model for every query. The more context matters, the more branching logic expands. What looks simple at import time becomes interpretive at execution time.
Interpretation is expensive.
Not only computationally, but conceptually. When access legality lives in dynamic tag evaluation instead of in a projected decision structure, reasoning about behavior becomes harder. Edge cases accumulate. Engineers start compensating with patches rather than clarifying the model.
Access legality is not a static attribute attached to a way. It is the result of a structured decision context. If that structure is not materialized ahead of time, it reappears as runtime complexity.
Turn Restrictions and Semantic Drift
Turn restrictions illustrate the same pattern. In OSM, they are relations referencing ways and nodes. This is perfectly natural in an editorial system. But a routing engine operates on directed edges. It splits ways, normalizes directions, and builds a traversal graph.
If the transformation from OSM relations to execution edges is not explicit and deterministic, semantic drift begins. Restrictions are applied inconsistently. Rare routing anomalies surface. Debugging requires digging back into relation structures that were never meant to represent execution semantics directly.
The system still “works" and most paths are correct. But correctness becomes probabilistic at the margins, and those margins are exactly where production incidents tend to live.
The problem is not incorrect data. It is the absence of a clear projection from editorial structure to execution model.
Where Performance Actually Breaks
Discussions about performance often focus on database tuning and computing capacity. These are important, but they rarely address the underlying cause of latency growth. I've seen this happen countless times.
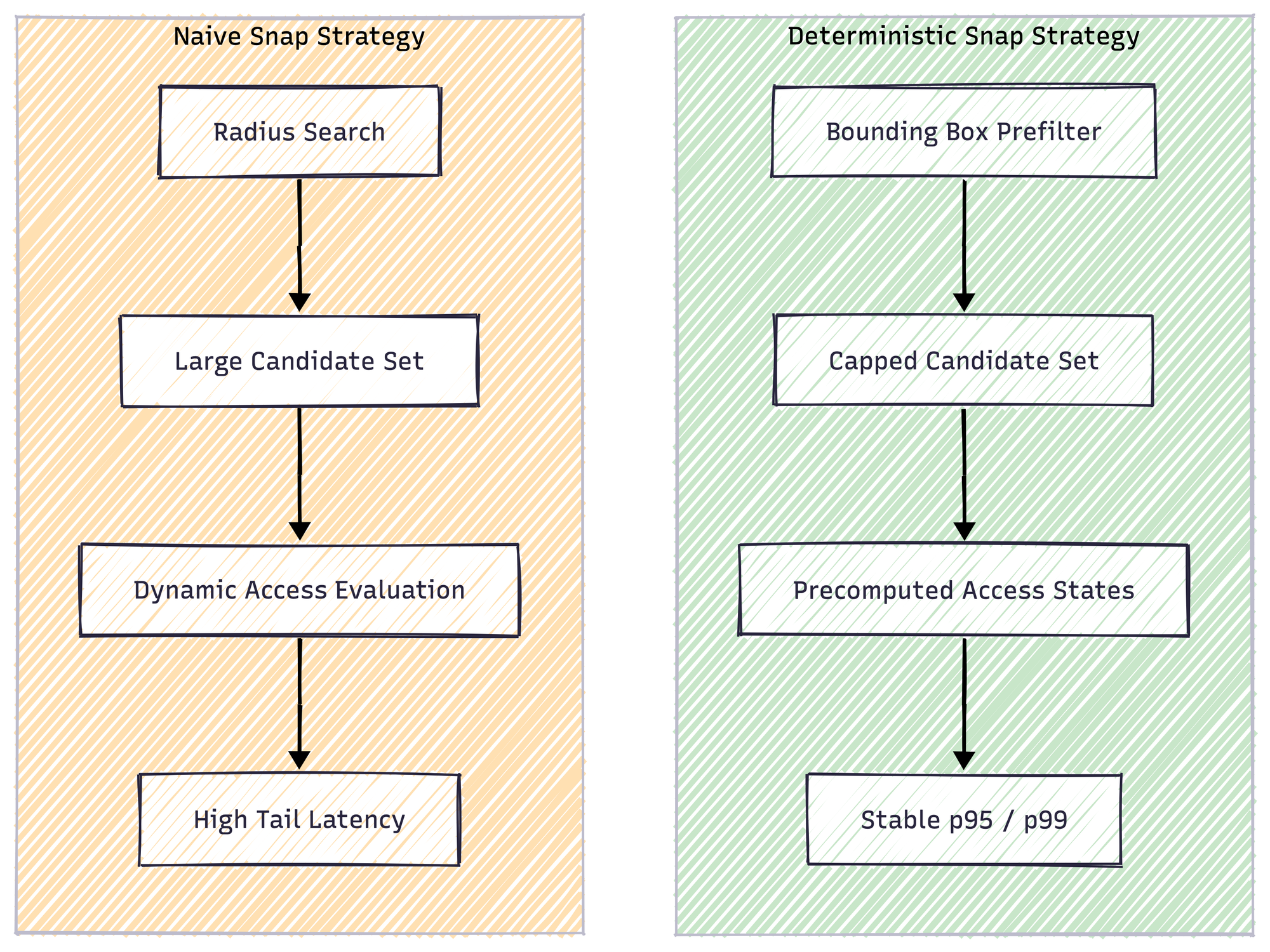
Snap-to-network behavior
In many implementations, snapping begins with a spatial radius search, followed by exact distance calculations for all candidates within that radius. The candidate set is then filtered based on access logic that is evaluated dynamically. Under moderate traffic, this is acceptable. Under sustained load, it becomes unstable.
The instability does not originate in the spatial index. It originates in the absence of structural bounds.
When the candidate search is unconstrained, the system allows pathological expansion. When access legality is resolved dynamically, every candidate carries interpretive overhead. Tail latency stretches not because the graph is large, but because the execution path is ambiguous.
Contrast to a projected model
If the snap strategy enforces a strict bounding-box prefilter that aligns with index selectivity, and if the number of candidates is capped deterministically before expensive distance computation, the behavior changes entirely. If access legality is precomputed into a decision-ready representation rather than reconstructed from tags, candidate filtering becomes structural rather than interpretive.
Suddenly, p95 stabilizes. Tail latency shrinks. Not because hardware improved, but because ambiguity was removed from the hot path.
The difference between triple-digit milliseconds and single-digit behavior is often not a matter of optimization. It is a matter of model clarity.
Flexibility Versus Determinism
OSM thrives on flexibility. Its model embraces evolving tags, community conventions, and contextual nuance. That is precisely why it is valuable.
Routing engines, particularly in scaling SaaS environments, cannot afford that flexibility at execution time. They require determinism. They require projection. They require separation between geographic input and decision logic.
When OSM is treated as the routing model rather than as the source of geographic truth, architectural responsibility is effectively delegated to editorial metadata.
At small scale this remains invisible but at scale, it becomes measurable in latency variance, in cloud cost, and in increasingly fragile execution paths. The misalignment is not dramatic. It is gradual. And that is what makes it dangerous.
Designing the Execution Model
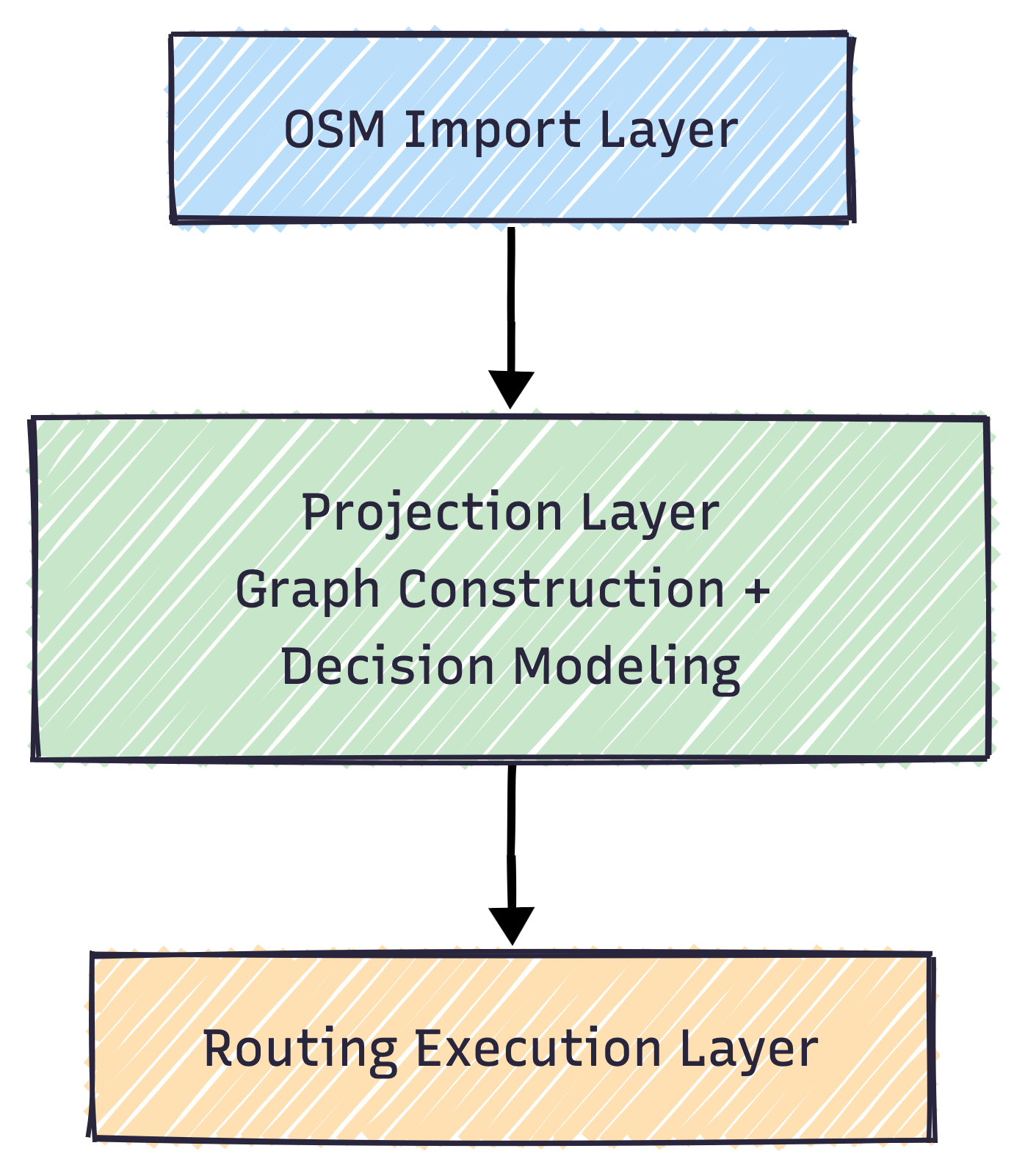
The alternative is not rejecting OSM. It is treating it with discipline.
OSM remains the input layer. A projection layer transforms it into a deterministic graph tailored for execution. Access legality becomes a modeled decision system. Turn restrictions are translated explicitly into edge semantics. Snap strategies operate within bounded, predictable constraints.
Once that separation exists, routing behavior becomes testable and explainable. Latency correlates with traffic instead of complexity. Cost reflects usage instead of structural ambiguity.
That is the difference between importing data and designing a routing core.
Conclusion
The real question is not whether OSM is sufficient for routing. It is! The question is whether the architectural responsibility for execution semantics has been taken seriously.
When OSM is treated as the routing model, the system implicitly delegates decision-making to editorial metadata. That delegation is convenient at first. It allows rapid progress. It avoids an explicit projection layer. It keeps the graph close to its source. But convenience at the modeling stage becomes cost at the execution stage.
Latency variance increases not because traffic grows, but because interpretation lives on the hot path. Edge-case inconsistencies emerge not because data is wrong, but because semantics were never made explicit. Infrastructure budgets expand not because the workload demands it, but because ambiguity demands compensation.
These effects are gradual. They rarely trigger a single catastrophic failure. Instead, they accumulate. Systems become harder to reason about. Performance becomes less predictable. Complexity moves from design time into runtime.
A routing core is not a dataset. It is an execution model.
That execution model must be designed deliberately: projected from OSM, not derived implicitly from it. Access legality must be modeled, not interpreted. Turn restrictions must be translated, not mirrored. Snap strategies must be bounded structurally, not tuned reactively.
Once that discipline is in place, the system behaves differently. Performance stabilizes because decision paths are deterministic. Correctness improves because semantics are explicit. Cost aligns with traffic rather than with structural ambiguity.
OpenStreetMap remains an extraordinary geographic source but importing it is not the same as designing a routing engine. And the difference is architectural, not incremental.
If your platform depends on OSM-based routing and latency or cost keeps drifting in the wrong direction, the root cause is rarely infrastructure alone. In many cases, it is structural.
That is exactly what I analyze in a structured Geo-API Performance & Model Audit.
Cheers!