Beyond Enterprise OOP: Building Clear, Composable Systems with PostgreSQL and Rust
PostgreSQL Guards the Facts, Rust Defines Intent, and Clarity Scales with the System

A recent discussion about treating database routines as Microservices resonated with something that had been forming in my work for years. If a routine is cohesive, versioned, and close to the data, it already behaves like a service: no extra runtime, no layers forwarding queries through a web framework, no duplicated rules. It’s a simple idea that cuts against decades of enterprise reflexes.

I’ve spent much of my career inside those reflexes. In enterprise environments built with Java or C# the architecture diagram usually came first and the data last. Every change passed through a procession of layers: repositories, entities, services, DTOs, mappers. Each tried to abstract something that was already concrete. Over time, those layers became barriers between what a system knows and what it does.
The same frustration appears everywhere: databases are treated as storage engines while the real logic hides in application layers. Yet most of what systems do is manage state transitions in data. When an order moves from pending to shipped, or a vehicle crosses a boundary, the meaningful part of the process happens at the data level, not in memory. Logic written close to data isn’t an anti-pattern. As Uncle Bob argues in Clean Architecture, the database is treated as a detail, hidden behind layers of indirection. In many data-driven systems that distance doesn’t add safety, it only obscures where decisions actually happen.
My work takes the opposite direction. Instead of isolating the database as a technical concern, I treat it as the foundation for rules that belong near the data. The application defines control flow and intent; the database defines truth and constraints. This clear division keeps logic visible while allowing the system to rely on the guarantees already built into the database.
This way of thinking grew naturally after years of watching mainstream object-oriented patterns outlive their usefulness. Once you stop assuming that every system needs multiple layers to stay clean, other shapes emerge.The database can continue to excel in areas such as integrity, consistency and atomicity, while the application can focus on validation, coordination and decision flow. The distance between data and logic shrinks without turning the database into a black box.
The important insight is that simplicity doesn’t mean the absence of structure; it means having just enough of it. A system can have boundaries and clarity without the scaffolding of enterprise OOP. The database doesn’t need to be passive storage, and the application doesn’t need to hide logic behind abstractions. Each part should do what it’s best at and remain transparent about it.
How I Solve It
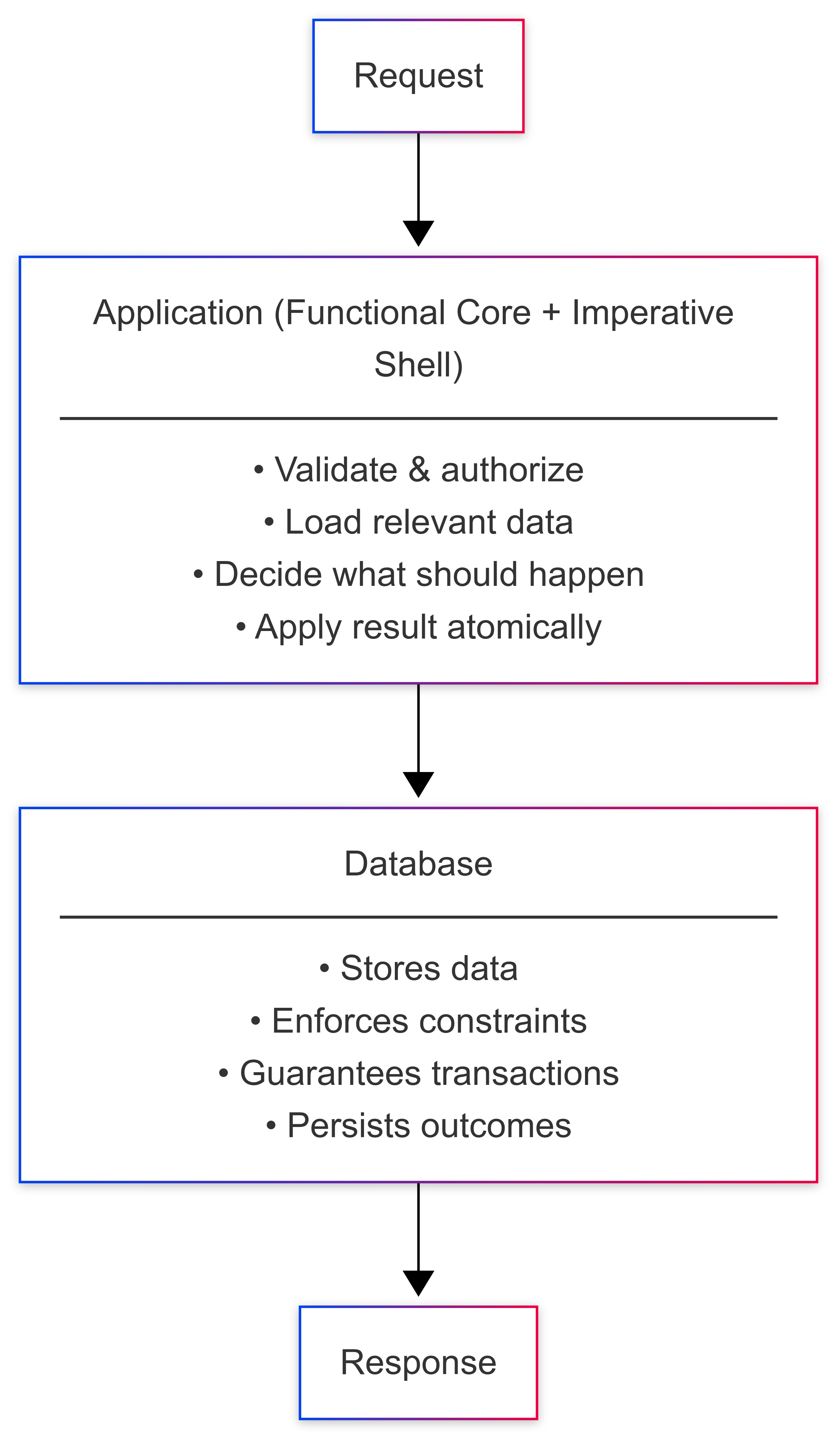
The guiding principle is proximity and keeping logic where it naturally belongs. The database shouldn’t execute control flow; its job is to define and protect truth. The rules that guarantee consistency live in the schema through constraints, keys, and declarative logic. The application handles decisions about what to check, what to allow, and what to reject. Those decisions stay explicit, traceable, and easy to test.
A simple example makes this clear. Take a rule like “an item name must be unique within a tenant". In many enterprise stacks this would be scattered across several layers: a repository checking for duplicates, a service applying the rule, a mapper translating objects, and a controller wrapping it all in an API response. That’s a lot of structure for one invariant.
In this approach, the rule lives in the database itself.
create table if not exists geofence_name_guard (
tenant_id text not null,
name_norm text not null,
geofence_id uuid not null,
unique (tenant_id, name_norm)
);
A unique constraint expresses it directly and atomically. The application doesn’t need to repeat that rule in its own logic; it only needs to interpret the outcome and respond accordingly. When a write fails because of a constraint violation, the system isn’t broken but it’s behaving correctly.
The logic around it stays minimal. Instead of an object graph, there’s a small, immutable data structure holding what the operation needs to know such as which record is being updated, whether it exists, and who currently owns the name. A simple decision function consumes that data and returns an outcome.
pub fn decide_rename(f: &RenameFacts) -> RenameDecision {
if !f.geofence_exists {
return RenameDecision::GeofenceNotFound;
}
match f.existing_guard_holder {
None => RenameDecision::Allow,
Some(holder) if holder == f.geofence_id => RenameDecision::Allow,
Some(_) => RenameDecision::NameTaken,
}
}
The surrounding code performs the orchestration: it loads the necessary data from the database, calls the decision function, and applies the result within one transaction. The decision remains pure and easy to test; the database enforces integrity; and the application layer makes the sequence explicit from start to finish.
pub async fn handle_rename_geofence(
pool: &PgPool,
tenant_id: &str,
geofence_id: Uuid,
new_name: &str,
new_name_norm: &str,
) -> Result<(), AppError> {
let geofence_exists: bool = sqlx::query_scalar(
"SELECT EXISTS(
SELECT 1 FROM geofence WHERE id = $1 AND tenant_id = $2
)"
)
.bind(geofence_id)
.bind(tenant_id)
.fetch_one(pool)
.await?;
let existing_guard_holder: Option<Uuid> = sqlx::query_scalar(
"SELECT geofence_id FROM geofence_name_guard
WHERE tenant_id = $1 AND name_norm = $2"
)
.bind(tenant_id)
.bind(new_name_norm)
.fetch_optional(pool)
.await?;
let facts = RenameFacts {
tenant_id: tenant_id.to_string(),
geofence_id,
new_name: new_name.to_string(),
new_name_norm: new_name_norm.to_string(),
geofence_exists,
existing_guard_holder,
};
match decide_rename(&facts) {
RenameDecision::GeofenceNotFound => Err(AppError::NotFound),
RenameDecision::NameTaken => Err(AppError::Conflict("Name already taken".into())),
RenameDecision::Allow => {
let mut tx = pool.begin().await?;
sqlx::query(
"UPDATE geofence SET name = $1 WHERE id = $2 AND tenant_id = $3"
)
.bind(&facts.new_name)
.bind(facts.geofence_id)
.bind(&facts.tenant_id)
.execute(&mut *tx)
.await?;
sqlx::query(
"INSERT INTO geofence_name_guard (tenant_id, name_norm, geofence_id)
VALUES ($1, $2, $3)
ON CONFLICT (tenant_id, name_norm)
DO UPDATE SET geofence_id = EXCLUDED.geofence_id"
)
.bind(&facts.tenant_id)
.bind(&facts.new_name_norm)
.bind(facts.geofence_id)
.execute(&mut *tx)
.await?;
tx.commit().await?;
Ok(())
}
}
}
This approach follows the same idea of keeping logic close to data without hiding behavior inside the database. Everything stays visible and deterministic. The database remains the authority on consistency, while the application coordinates the flow of decisions and writes. Together they form a conversation that’s easy to follow: the request expresses intent, the database enforces the rules, and the result becomes part of the system’s record.
The goal isn’t to reduce code for its own sake, but to remove what doesn’t add meaning. When a constraint already defines a rule, there’s no reason to simulate it again in code. When a decision can be expressed with simple data and a clear outcome, there’s no need to wrap it in layers of abstraction. The database guarantees integrity; the application keeps intent explicit.
This way of building software invites a closer look at where complexity really comes from and how much of it is self-inflicted. Many systems grow heavy not because of the problem they solve but because of the frameworks and patterns wrapped around them. When each layer stops trying to hide the next, the design starts to feel lighter and more direct.
A Simpler System, Still Composable
This way of working changes how a system takes shape. Each feature becomes a small, self-contained slice, a single path from input to outcome. It defines its data structures, decision logic, and transaction, and doesn’t depend on shared models or global services. This structure aligns naturally with event modeling, where every action is seen as a complete scenario: what information arrives, what decision is made, and what state change follows. By treating each slice as its own closed loop, the system remains easy to reason about and extend.#
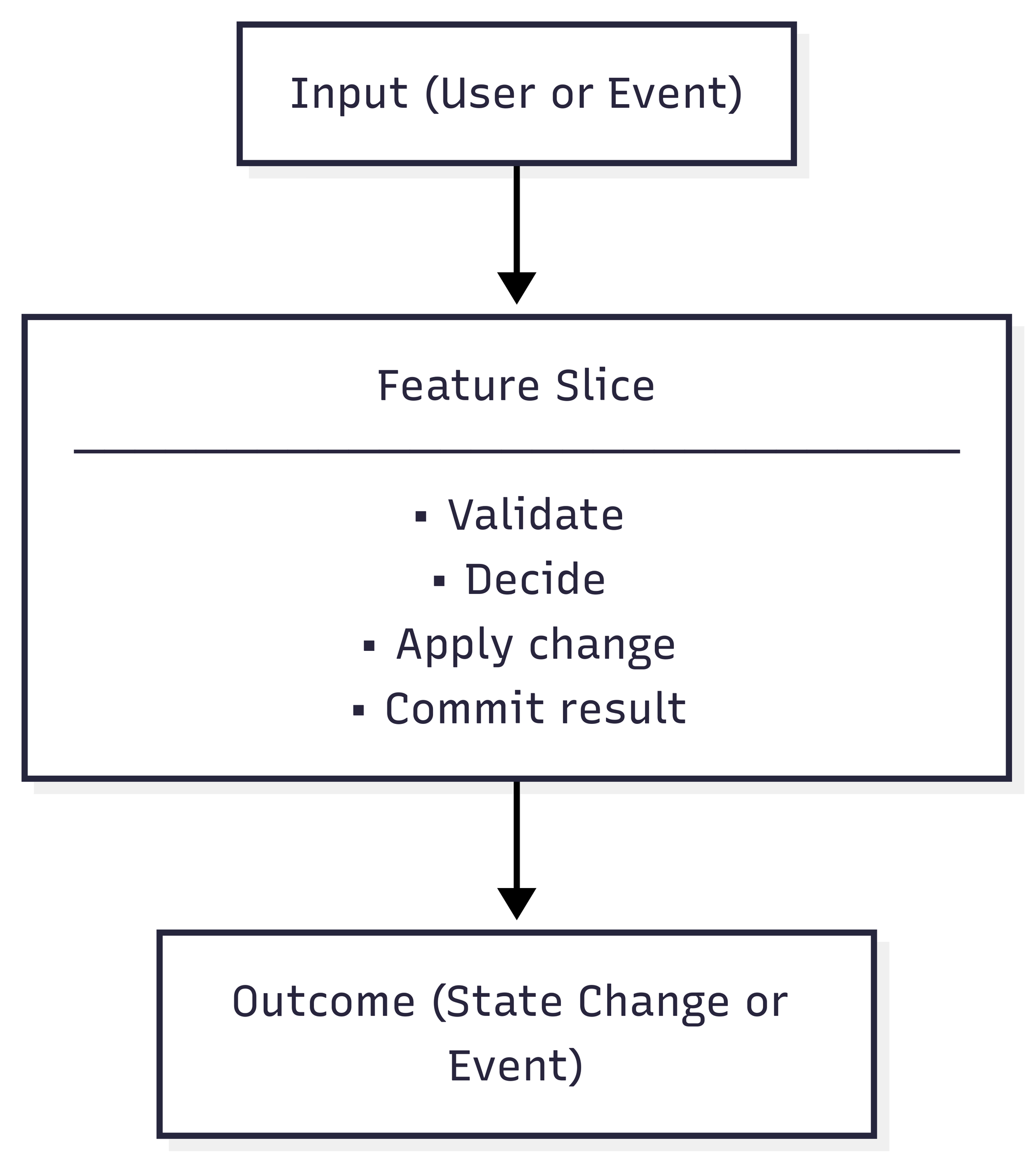
Each slice operates on its own data and logic but shares a common foundation. The database ensures integrity and atomicity, while the application layer keeps control flow visible. Because slices interact only through persisted state or well-defined events, they remain independent. One slice can evolve, be replaced, or scale separately without disturbing the rest. The system grows by addition instead of revision; new behavior joins alongside existing flows rather than reshaping them.
This separation makes scaling straightforward. When a slice grows or needs a different lifecycle, it can move into its own service without redesign. The interface is already simple: SQL in, decision out, commit. The system doesn’t start as Microservices; it grows toward that naturally as boundaries solidify.
It also simplifies what many traditional systems tend to over-complicate. There’s no ORM state to coordinate, no long chain of dependencies to follow before reaching the data. The logic sits next to the facts, and each request describes a complete piece of work from start to finish.
At runtime the flow stays predictable. A request comes in, the Rust shell validates it, the slice executes its sequence: load the relevant data, run the decision, apply the result in a single transaction. The path is visible in logs and traces, and when something breaks, it fails in one place that’s easy to see and fix.
This simplicity isn’t fragile. It’s controlled. PostgreSQL handles transactions and concurrency; Rust enforces ownership and error handling. Together they create boundaries that keep features independent without coordination frameworks.
Even under load, the behavior stays the same. Each slice reads only what it needs, makes its decision, and applies the result in a single transaction. There are no shared caches to refresh, no domain objects drifting out of sync with persisted state. The surface area remains small, and the logic stays transparent regardless of scale.
The aim is to keep the distance between data and decision short. Logic stays visible, and every effect is deliberate. The database maintains consistency; the application defines intent. Each side reinforces the other, creating a system that is simple to follow and easy to trust.
Over time, the system grows by addition rather than accumulation. New behavior arrives as new slices, each with its own data structures, decision logic, and transaction. When a slice is complete, it stands on its own. Nothing else needs refactoring or layering on top. The architecture remains steady because every part keeps the same clear boundaries it started with.
It’s a modest structure but one that holds up well over time. It doesn’t try to impress with complexity or patterns; it works because each part knows its role. Logic and data stay close, decisions stay visible, and every change leaves the system as understandable as it was before.
What This Avoids
Enterprise systems often grow around abstractions meant to protect developers from their own tools. ORMs, repositories, service locators, dependency injection frameworks each starts as a convenience and ends as a layer that hides what’s really happening. These structures create distance between the data and the behavior that depends on it. Over time, the system becomes a maze of intermediaries translating the same values back and forth.
The approach I describe keeps that distance short. The database already understands how to guarantee integrity; there’s no need to reimplement it in code. A unique index, a constraint, or a transaction does the job directly and consistently. Rather than competing with these mechanisms, the application cooperates with them.
By treating the database as the authority on state and using Rust to define how that state may change, the system loses none of its structure but gains a great deal of clarity. Queries are explicit. Decisions are explicit. Every line of code exists for a reason that’s visible in the logs and reproducible in tests.
This clarity also removes much of the accidental complexity around data flow. There’s no object graph to manage, no lazy loading to debug, no hidden state waiting to surprise you under load. The service does one thing at a time, and you can read its path from request to commit without guessing what happens in between.
The same principle applies to evolution. When a rule changes, you update a decision function or a single SQL statement. There’s no cascade of side effects in generated code or configuration. The shape of the system remains stable while the rules inside it evolve freely.
It’s a simpler kind of discipline. Instead of controlling complexity with more architecture, you limit it by keeping each part honest about its role. PostgreSQL guards the facts. Rust moves the data safely through the system. The result is a codebase that grows without losing transparency, and a system that doesn't fight you as it matures.
Conclusion
Many large systems grow heavy because they try to protect developers from their own tools. Frameworks and layers (ORMs, repositories, service locators, dependency injection) begin as conveniences and end as barriers. Each one adds distance between the data and the logic that depends on it. Over time, the system spends more effort maintaining its structure than expressing its rules.
Over the years, I’ve grown skeptical of architectures that try to protect developers from the tools they use. Layers of abstraction promise freedom from change but often achieve the opposite. They make small changes expensive and simple ideas hard to express. The systems that survive are not the most abstract; they are the ones that remain understandable.
The model I describe here is not new or revolutionary. It’s closer to rediscovery. Many of the ideas we now label “modern architecture” existed long before frameworks. What’s different today is the maturity of the tools. PostgreSQL offers transactional consistency, indexing, and performance that used to require specialized systems. Rust gives safety and precision without runtime overhead. Combined, they allow a style of development that feels closer to reasoning about a problem than managing an architecture.
I see this very much as a step away from the object-oriented style that shaped most enterprise systems I worked on. After years of practicing it, I no longer find the trade-offs worthwhile. The constant modeling of behavior into classes and hierarchies creates distance from the data, not clarity. Objects try to represent change through mutable state and inheritance, yet most real-world systems revolve around immutable facts and clear transitions.
Microservices, on the other hand, are a different matter. I do not reject them, but I approach them differently. In my view, they should emerge from well-defined slices of behavior, not from diagrams drawn in advance. A feature that already has a clean boundary and minimal dependencies can become a service naturally, without a framework or ceremony around it.
When logic and data stay close, the feedback loop tightens. You can see immediately how rules behave, test them as small decisions, and deploy them without fear of side effects. It’s not a call to push everything into the database or to rewrite systems in Rust. It’s an argument for clarity, for designing systems where the flow of information is short, explicit, and easy to follow.
That’s the goal in all of this: less complexity, more clarity. A system that explains itself when you read it and where every part does exactly what it’s meant to do, and nothing more.
Cheers!